Global Site
Displaying present location in the site.
Explaining GenAI Output with the LLM Explainer
Vol.19 No.1 Special Issue on NEC BluStellar: NEC BluStellar Driving the Future of Digital Transformation — A Value Creation Model Pioneered by AI, Security, Data Management, and ModernizationEnterprises increasingly would like to use Large Language Models (LLMs) to enhance operational efficiency, yet verifying their accuracy remains a critical challenge. Our LLM Explainer helps build trust and transparency by linking AI-generated answers to their exact source sentences. This allows fast and efficient verification of AI output, particularly suitable for high-risk domains. LLM Explainer achieves this through automated data generation and the training of efficient attribution models. Evaluation shows it obtains superior accuracy while operating at 1/70th of the computational cost of larger models with lower accuracy. For decision-makers, it transforms the use of LLMs from a potential vulnerability into a strategic capability that strengthens confidence in mission-critical intelligent systems.
1. Introduction
Large Language Models (LLMs) are rapidly becoming core components of enterprise operations, driving automation, insight generation, and customer engagement. However, their growing adoption also amplifies critical concerns around reliability, transparency, and compliance. One of the most pressing challenges is the prevention of inaccurate or misleading outputs—often referred to as hallucinations—which can erode trust, disrupt workflows, and expose organizations to regulatory or reputational risk. As enterprises seek to leverage LLMs for high-stakes decision-making, ensuring the verifiability of AI-generated content has become essential to maintaining accountability, operational integrity, and stakeholder confidence.
Our technology addresses this challenge by linking LLM answers to specific source sentences. This enable the efficient verification of LLM output and is an essential capability for organizations requiring transparency, auditability, and reliability in AI-driven outputs.
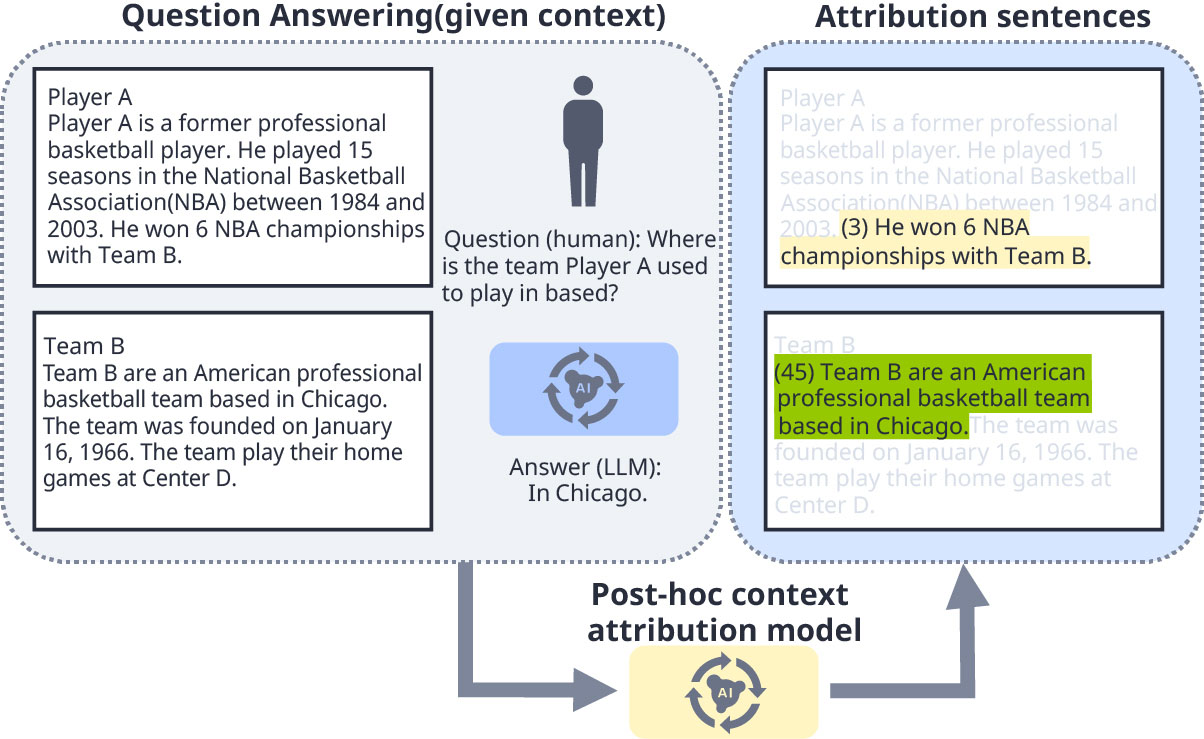
Our novel approach, the LLM Explainer, leverages advanced LLMs to automatically generate high-quality synthetic training data that enables smaller, efficient models to perform real-time, sentence-level context attribution with high accuracy1). Context attribution is the task of linking an LLM-generated sentence to a source sentence that supports or refutes the LLM-generated sentence. Unlike existing methods that rely on coarse document-level evidence or computationally expensive inference, LLM Explainer delivers fast and precise attribution, significantly reducing the need for costly human annotation and enabling scalable deployment across diverse domains. For an example, see the figure below.
For NEC’s customers—spanning government agencies, telecommunications providers, financial institutions, and transportation sectors—this technology offers concrete business benefits: enhanced trustworthiness of AI-generated content, improved operational efficiency through faster and more accurate verification of answers, and enabling compliance with stringent regulatory requirements for transparency and accountability. Our user studies demonstrate that LLM Explainer's attribution models help end users verify AI outputs more quickly and accurately.
By using LLM Explainer for context attribution, users gain a robust, scalable tool that strengthens the reliability of automated question answering and supports mission-critical decision-making processes. This advancement enables to deliver secure, transparent, and trustworthy AI technologies that meet the complex needs of regulated industries and public sector organizations worldwide.
Fig.1 description: Given a question, an LLM-generated answer, and context (from human input or retrieval), the model identifies supporting sentences within the context. Our user study shows that presenting these supporting sentences helps users verify LLM answers more quickly and accurately.
 Click to Enlarge
Click to Enlarge2. System Overview
Our solution presents an innovative automated source attribution system that enables real-time verification of AI-generated text while maintaining operational efficiency. The system provides immediate traceability by automatically identifying and citing the specific source materials that support each AI-generated response.
The technology operates through a post-verification approach that analyzes AI-generated content after generation, eliminating the need to modify existing AI systems or workflows. The core architecture consists of three integrated components:
- (1)Training Data Generation Engine: Automatically creates high-quality verification training data using advanced AI techniques, eliminating dependence on expensive human annotation
- (2)Lightweight Attribution Models: Deploys efficient, cost-effective AI models fine-tuned specifically for source verification tasks
- (3)Real-time Verification Interface: Provides immediate source attribution with clear visual indicators of supporting evidence
3. LLM Explainer
Existing source attribution systems typically require extensive training data to accurately identify which parts of reference documents support AI-generated responses. Traditional approaches demand costly human annotation processes, creating implementation barriers for organizations seeking to deploy verification systems across large-scale operations. Our solution addresses this challenge through automated training data generation that eliminates human annotation requirements while producing superior results.
Source attribution identifies which portions of a trusted set of documents support specific AI-generated question-answer pairs. In formal terms, given a query, its AI-generated response, and organizational context documents consisting of multiple sections, the system must identify the specific document sections that fully support (or refute) the generated response. To train efficient verification models without expensive human oversight, we developed an automated data generation approach using advanced AI systems.
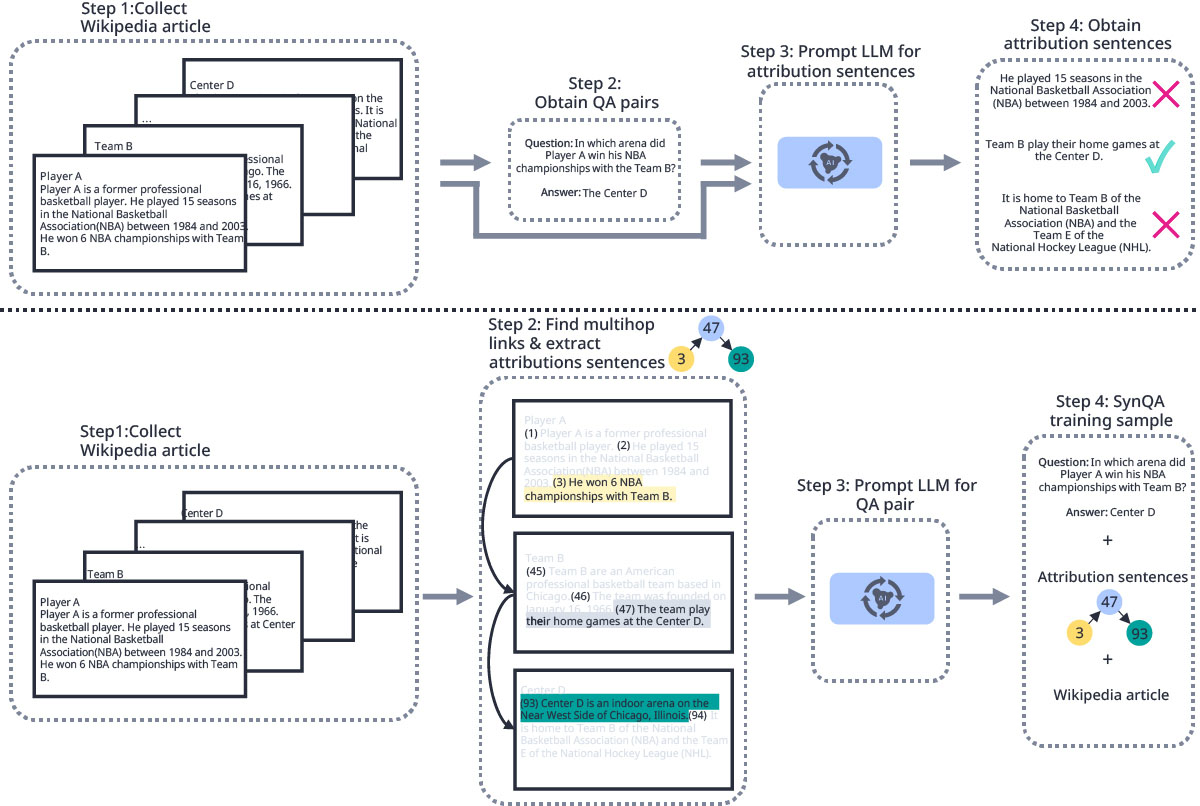
We implement two distinct methods for automated training data creation. The baseline approach uses a discriminative method: existing question-answer pairs and their organizational context are processed by an AI system to identify supporting document sections, which then train smaller verification models through knowledge transfer. In contrast, our proposed method employs a generative approach: selected document sections are used by an AI system to generate question-answer pairs that are fully supported by these sections. This approach better utilizes AI systems' natural text generation capabilities while ensuring clear evidence trails in the training data.
3.1 Training Setup
Data Generation for training LLM Explainer operates through three integrated components: context selection, question-answer generation, and distractor integration. This comprehensive approach ensures training data reflects real-world enterprise scenarios where verification systems must distinguish between relevant and irrelevant information sources.
- (1)Context Collection Strategy: We utilize comprehensive knowledge repositories as our data source, as each document contains coherent, interconnected information relevant to specific business domains. The system employs two collection strategies optimized for different enterprise use cases. For customer service and support scenarios, individual documents are selected for dialogue-focused generation using their content sections as context. For complex analytical tasks requiring multi-source reasoning, the system identifies document sections containing cross-references and follows these connections to create information chains between documents, maintaining semantic coherence while enabling sophisticated reasoning patterns that mirror real enterprise decision-making processes.
- (2)Question-Answer Generation Process: Using the selected contexts, advanced AI systems generate realistic question-answer pairs that mirror real world scenarios. For single-document contexts, the system creates dialogue-focused question-answer sequences where questions build upon previous context, simulating customer service interactions or internal consultations. For cross-referenced documents, the system generates questions requiring information synthesis across multiple sources, encouraging multi-source reasoning typical of regulatory compliance analysis or technical troubleshooting.
The system receives complete reasoning chains as ground truth evidence and generates question-answer pairs answerable only through this evidence. This produces training samples requiring information integration across multiple enterprise documents, reflecting real-world scenarios where employees must synthesize information from various organizational sources to provide accurate responses. - (3)Distractor Integration: To ensure training data reflects realistic enterprise environments where verification systems encounter multiple similar documents, each training sample is augmented with distractor documents. Using advanced embedding techniques, the system identifies each document in the training collection and selects up to three distractors with high semantic similarity to the source documents. These distractors share thematic elements with source documents but lack the specific information needed to answer the questions.
This process increases training data complexity, producing verification models better equipped to handle diverse scenarios where relevant and irrelevant documents often appear together in search results or document repositories.
3.2 Strategic Advantages
Our approach delivers three critical advantages for enterprise AI verification implementations:
- (1)Leverage AI Strengths: Rather than requiring AI systems to perform classification tasks for which they are less optimized, our approach utilizes their superior text generation capabilities, resulting in higher-quality training data and more reliable verification models.
- (2)Create Comprehensive Training Scenarios: The system generates diverse training samples encompassing both conversational interactions and multi-source analytical reasoning, producing training data that reflects a wide spectrum of enterprise AI applications.
- (3)Ensure Evidence Traceability: Generated questions maintain clear attribution paths since they derive from specific document sections, guaranteeing that trained verification models can provide precise source citations required for enterprise accountability and compliance requirements.
Top of Fig.2: The baseline method for synthetic attribution data generation. Given context and question-answer pairs, we prompt an LLM to identify supporting sentences, which are then used to train a smaller attribution model. However, this discriminative approach may yield noisy training data as LLMs are less suited for classification tasks. Bottom of Fig. 2: Our data generation pipeline leverages LLMs’ generative strengths through four steps:
- (1)Collection of articles as source data.
- (2)Extraction of context attributions by creating chains of sentences that form hops between articles.
- (3)Generation of QA pairs by prompting an LLM with only these context attribution sentences.
- (4)Compilation of the final training samples, each containing the generated QA pair, its context attributions, and the original articles enriched with related distractors.
 Click to Enlarge
Click to Enlarge4. Application and Evaluation of LLM Explainer
We conducted comprehensive validation of LLM Explainer’s source attribution technology across multiple scenarios to demonstrate its practical utility and performance advantages. Our evaluation compares our LLM Explainer models against two primary alternatives:
- (1)Large-Scale Zero-Shot AI Systems: Representing the current industry standard, these systems use massive AI models (like Llama 70B2) with 70 billion parameters) without specialized training, offering broad capability but requiring substantial computational resources.
- (2)Human-Annotated Training Approaches: Traditional methods using expensive human oversight to create training data, representing the established approach for organizations with extensive annotation budgets.
4.1 Evaluation Framework and Metrics
Enterprise AI verification systems must balance three critical performance factors: accuracy in identifying correct sources, completeness in finding all relevant evidence, and overall reliability. We measure system performance using standard metrics adapted for source attribution:
- (1)Precision: The percentage of identified sources that support the AI-generated content, indicating system reliability and reducing false positive attributions that waste user time.
- (2)Recall: The percentage of relevant sources successfully identified by the system, measuring completeness and ensuring comprehensive evidence coverage.
- (3)F1 Score: A balanced measure combining precision and recall, providing overall system effectiveness assessment for enterprise deployment decisions.
4.2 Results of Automatic Evaluation
We describe the results per task.
- (1)Direct Question-Answer Verification: Against large-scale zero-shot systems, our 1-billion parameter model achieved 96.1% F1 score compared to Llama 70B's 95.5%, while requiring 70 times fewer computational resources. This translates to significant cost savings for when running attribution queries.
- (2)Conversational Support Systems: In multi-turn dialogue scenarios, LLM Explainer’s attribution models achieved 91.3% F1 score versus 88.1% for 70-times-larger zero-shot systems, showing effectiveness for real-time customer engagement applications.
- (3)Cross-Domain Generalization: LLM Explainer showed superior generalization when deployed on content types different from its training data, a critical requirement for enterprise applications. In conversational scenarios, the system achieved 91.3% F1 score compared to 88.1% for the 70-times-larger Llama 70B model. Furthermore, our automatic data generation approach ensures that fast and highly accurate LLM Explainer models can easily be created for specific business domains.
4.3 Results of User Study
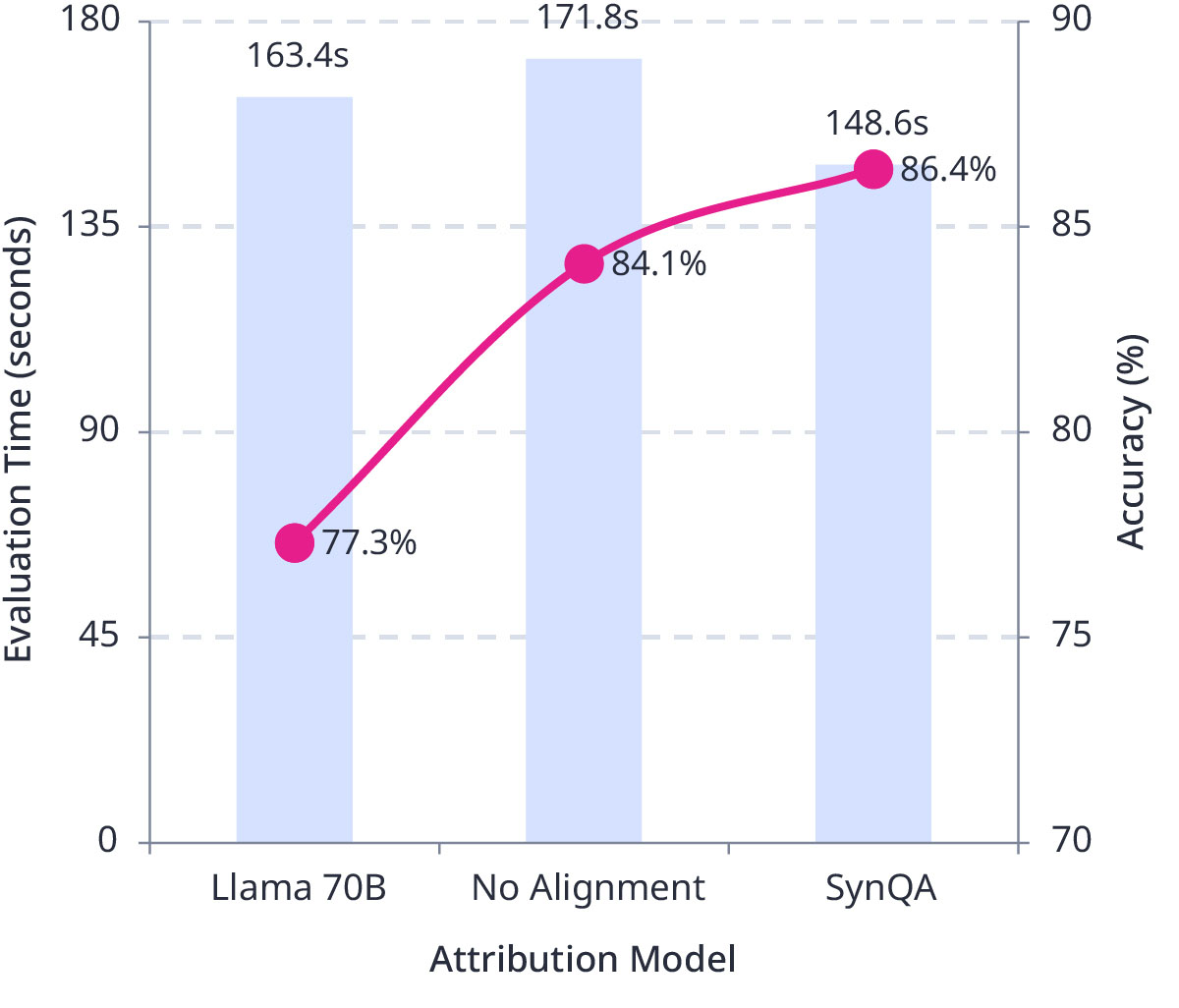
- (1)User Study Design: To validate the practical impact of our source attribution technology on end-user productivity, we conducted a controlled study with 12 participants evaluating AI-generated answer verification under three conditions. Participants were presented with questions, AI-generated answers, and supporting documentation, then asked to determine answer correctness. The study compared three scenarios: (1) manual verification without any attribution assistance (“No alignment”), (2) verification using basic zero-shot attribution highlighting (“Llama 70B”), and (3) verification using our LLM Explainer attribution system (“SynQA”). Using a rigorous within-subjects design with counterbalanced ordering to prevent learning effects, we measured both verification speed and accuracy across all conditions to assess real-world utility for validating AI-generated content.
- (2)Significant Performance Improvements: The LLM Explainer system delivered measurable productivity gains for users performing verification tasks. Participants using LLM Explainer completed verifications in an average of 148.6 seconds compared to 171.8 seconds for manual verification without assistance—a 13%-time reduction that translates to substantial efficiency gains in high-volume enterprise environments. More importantly, verification accuracy improved to 86.4% with LLM Explainer compared to 84.1% for manual verification and 77.3% for basic zero-shot attribution (Fig.3). This combination of faster completion times and higher accuracy demonstrates clear business value, as organizations can process more verification tasks while reducing errors that could lead to compliance issues or operational problems.
 Click to Enlarge
Click to Enlarge4.4 Enterprise Value of LLM Explainer
The validation results translate directly to measurable business benefits for organizations implementing source attribution technology. LLM Explainer delivers high accuracy while reducing computational costs by over 98% compared to large-scale alternatives, enabling deployment on standard business hardware without specialized infrastructure. The system's ability to automatically generate training data eliminates the months-long human annotation processes that typically cost a significant amount of money, while maintaining superior performance across diverse enterprise scenarios from regulatory compliance to technical documentation verification.
5. Conclusion
Our automated source attribution technology via LLM Explainer addresses a critical challenge facing enterprise AI deployments: enabling organizations to harness AI productivity benefits while maintaining the accountability and verification standards required for mission-critical operations. Through the development of our automated training data generation and efficient LLM Explainer models, we have demonstrated a practical solution that eliminates the cost and complexity barriers traditionally associated with AI verification systems. The technology delivers superior performance compared to both expensive large-scale AI alternatives and traditional human-annotated approaches, while operating efficiently on standard enterprise hardware.
LLM Explainer consistently outperformed zero-shot systems that are 70 times larger, while demonstrating robust cross-domain generalization essential for organizations with varied content types and business processes. The system's ability to automatically generate high-quality training data eliminates dependence on costly human annotation processes, enabling rapid deployment across new departments or content domains without extensive preparation periods. These capabilities lower the barrier of adopting AI systems in regulated environments, customer-facing applications, and mission-critical workflows where verification and accountability are paramount.
References
 Gorjan Radevski et al.: On Synthesizing Data for Context Attribution in Question Answering, the the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), July 2025
Gorjan Radevski et al.: On Synthesizing Data for Context Attribution in Question Answering, the the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), July 2025Authors’ Profiles
SYED Shahbaz
Senior Research Engineer
NEC Laboratories Europe
Senior Research Engineer
NEC Laboratories Europe
LAWRENCE Carolin
Manager & Chief Research Scientist
NEC Laboratories Europe
Manager & Chief Research Scientist
NEC Laboratories Europe
GASHTEOVSKI Kiril
Senior Research Scientist
NEC Laboratories Europe
Senior Research Scientist
NEC Laboratories Europe
IWAI Takanori
Assistant General Manager
NEC Laboratories Europe
Assistant General Manager
NEC Laboratories Europe
ITO Kunihiro
Secure System Platform Research Laboratories
Researcher
Secure System Platform Research Laboratories
Researcher
ARAKI Toshinori
AI Technology Services Division
Senior Manager
AI Technology Services Division
Senior Manager


