
Global Site
Displaying present location in the site.
October 4th, 2021
Machine translation is used partially for this article. See the Japanese version for the original article.
Introduction
In the previous article, you learned about "design for failure".
This time, lets learn about "Single Point Of Failure".
It is often abbreviated to "SPOF", which means a point of failure that would bring down the entire system.
The key point here is that the point where the failure occurred is "single".
Let's take a look at the figure used last time to see where the SPOF is.
SPOF and Redundancy
Did you know that almost all of the parts shown in this figure are SPOF?
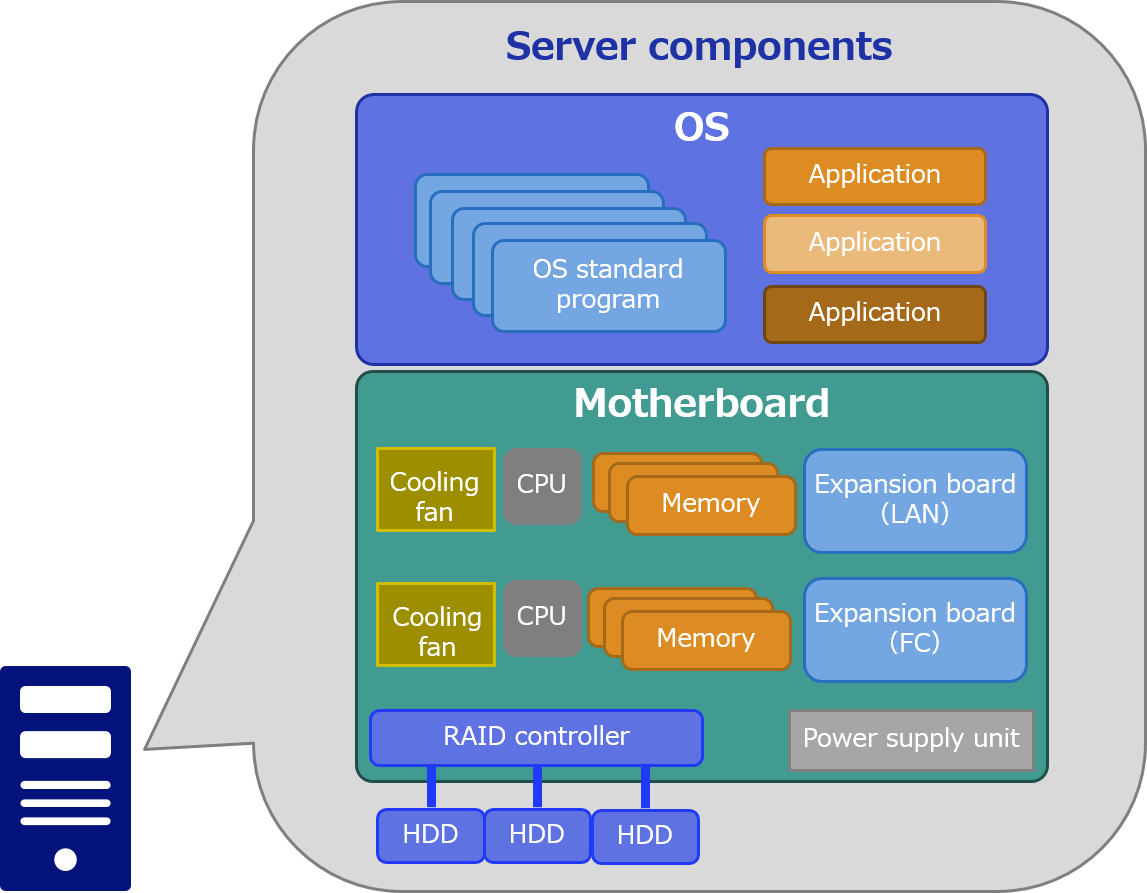
In the figure above, there are multiple HDDs, which are made redundant by a RAID controller.
Therefore, HDD is not SPOF, but other parts are SPOF.
You might say, "There are 2 cooling fans, so it is not SPOF!".
However, if there is only one cooling fan for each CPU, then it is SPOF.
If the cooling fan fails, the CPU will not be able to cool down, and the CPU will not work due to thermal runaway. As a result, the system will go down.
So what can we do to prevent SPOF? It can be solved by making the part that becomes SPOF redundant.
The cause of SPOF is the existance of a single part that can bring down the entire system in the event of a failure, so we should make that point redundant and have multiple points.
In this way, even if one part fails, as long as the other parts work properly, the entire system can be prevented from going down.
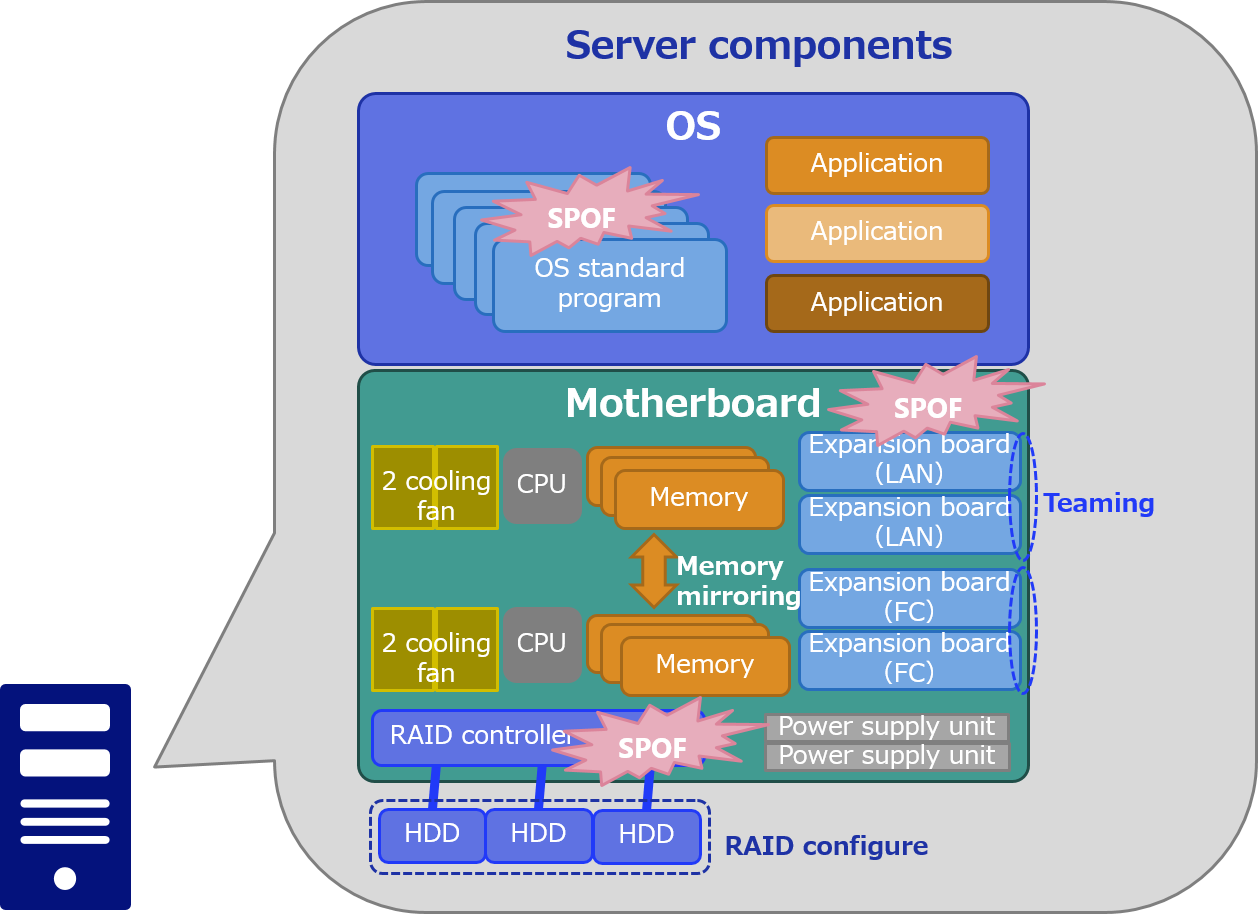
The means of redundancy vary from part to part, so let's take a look at them one by one.
(The following description focuses on the technologies generally used in PC servers.)
- CPU:
If the motherboard and OS are supported, the failed CPU can be separated and the rest of the CPU can continue to operate.
However, it seems that many recent PC servers do not support it.
- Memory:
Motherboards with memory mirroring can be redundant in multiple memory.
However, the OS can recognize half the amount of memory on board.
- HDD:
It can be redundant to configure a RAID (e.g. mirroring) with multiple HDDs.
In general, multiple HDDs are connected to a RAID controller to configure a RAID. Even if there is no RAID controller, it is possible to implement RAID software-like with the function of the OS. Performance is lower than using a dedicated RAID controller, but the cost can be reduced.
- Expansion board (LAN/FC):
There is a technology* that bundles multiple interfaces and treats them as one virtual unit. By providing multiple expansion boards and bundling the interface of each board, it is possible to accommodate board failures. - * In the case of LAN, it is called teaming and bonding.
FC is also called multipath I/O or device mapper multipath. There may be differences in OS culture in this field, so let me skip the detailed explanation.
- Power supply unit:
Multiple power supply units make a system redundant.
In most cases, UPS (uninterruptible power supply) is added to this system to prevent power outages. UPS is very effective as a countermeasure against temporary power outages and blinking.
- Cooling fan:
It allows for redundancy to place two cooling fans in the direction of the wind flow.
Even if one of the fans stops, the other fan can still deliver air.
Conclusion
Now, there are actually some components that are not yet redundant (SPOF).
These are the motherboard, RAID controller, and OS*.
When you reach this stage, it can not be solved with a single server. Therefore, you might ask yourself, "Why don't I get another server and make it redundant?". This is an idea that will naturally come up. But let's learn about this in another article.
* As for the applications that run on the OS, it depends on the specifications of each application, but applications themselves are rarely redundant within a single OS, so the OS and everything that runs on it are treated as non-redundant.
Tips...
There is fault-tolerant servers that redundant almost all components including the motherboard, but the OS part will still be SPOF.