
Global Site
Displaying present location in the site.
November 20th, 2017
Introduction
Do you know the idea of "design for failure"? It is the idea of system design based on the thought that system failure is inevitable. Failure is inevitable..., what does it mean? It means that we should treat every equipment composing the system as "what is bound to fail in the future". This is a little abstract so, let us use a concrete example.
In case you are operating website with single server, which component of the system is supposed to have failure? When you say "server went down", there are several faulty part considered to be the cause of the failure. Let us begin with the objective of the hardware.
Hardware
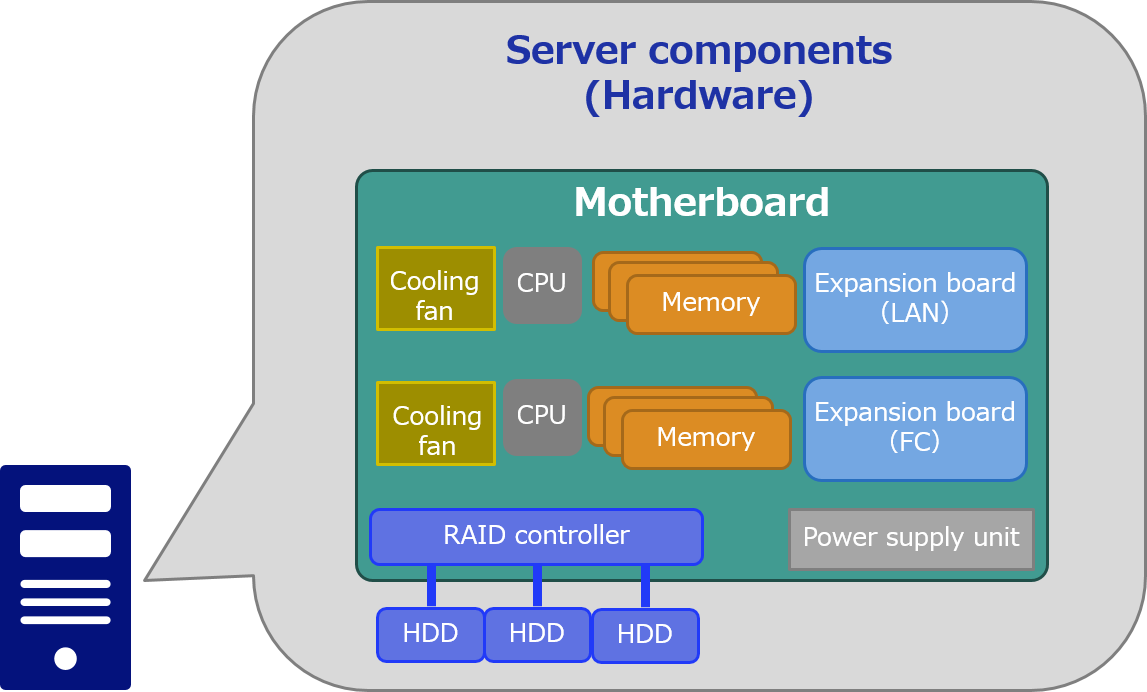
Not only CPU, memory and disk, but also motherboard, power unit and cooling fan can be listed as server components. Moreover, if you have added extension board for LAN, FC (Fiber Channel) and RAID*, these are also components of the server. Although there are differences in failure frequency (durability), every component is treated as "what is bound to fail in the future" in the "design for failure" perspective.
*Even if RAID is a technology to improve failure durability or performance by combining multiple disk drives, we also need to assume the failure of RAID controller itself.
Software
Next, how is the software prospect of view? What comes first is a failure of OS (Operating System) itself. The failure can be caused by OS bug (defect in the program) or security vulnerability. Also same failure caused by bug or security vulnerability can be occurred at application which provides website functions. Furthermore, we need to keep in mind that high-load condition due to rapid access increase to the website can also be assumed as a failure.

Network
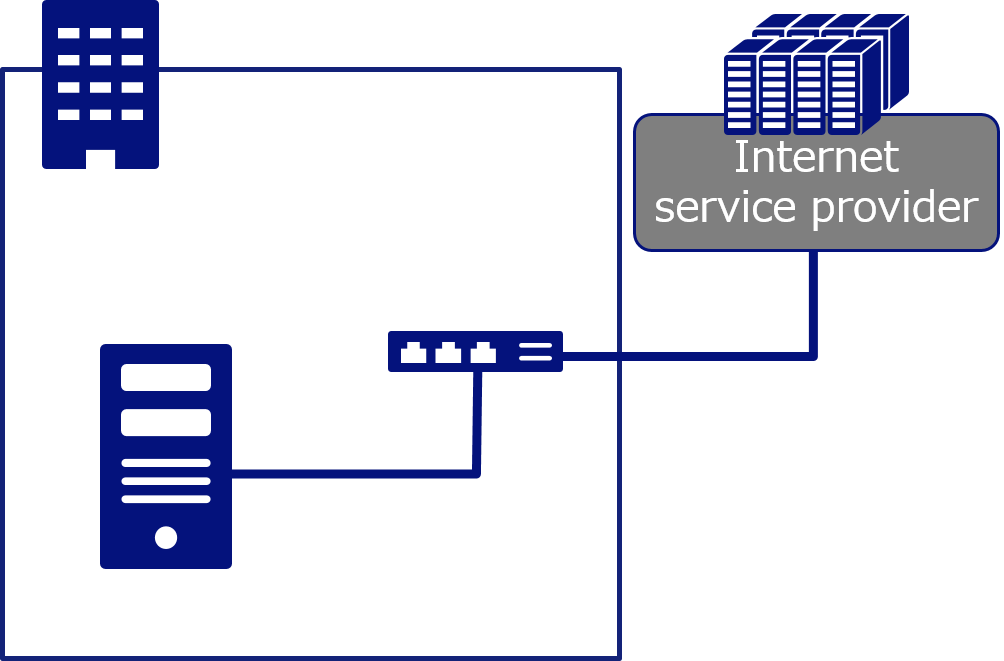
Now, we have reviewed the failure to be caused by both hardware and software in regard to single server operation, however we need to take one more important element into consideration. In this blog, we picked up "website operation" as an example, so we have to broaden our scope to network devices and systems, which are connecting the users accessing to the website with the server running website.
What comes first is a failure of network devices or cables connected to the server. In many cases, cable failure means cable disconnection. Also, when it comes to high performance network equipment which requires dedicated OS, we need to consider the failure due to the bug or security vulnerability of OS. Since we are considering website running environment, we also need to assume a network failure at internet provider side.
Conclusion
Even in case you are operating the website with simple configuration of single server, you need to design the system while expecting so many possibilities of failure. "Design for failure" indicates how to consider failure possibility and its measure as above, and it is also the general principle to design the robust system. Don’t just be frightened by the unexpected but possible failure. Instead, let us prepare for it by thinking that failure is inevitable, then you can design a highly-reliable system.
And what is more... as a matter of fact, you also have to assume for the failure of whole building where server is located (power outage, building collapse due to large-scale disaster, and so on), but we give this a rain check.