Global Site
Displaying present location in the site.
Predictive Analytics Solution for Fresh Food Demand Using Heterogeneous Mixture Learning Technology
Vol.10, No.1 December 2015, Special Issue on Enterprise Solutions to Support a Safe, Secure and Comfortable LifeNEC's demand-predictive order automation solution uses our original "heterogeneous mixture learning technology" to provide highly accurate forecasting of demand for Fresh Food by analyzing the correlative relationships between various factors such as sales performance by time slot, what goods are discarded or sold out, as well as weather information. This solution automatically orders the optimal amount of goods based on the predicted demand, the inventory at retail stores, and the number of goods that are scheduled for delivery. By optimizing the order amount, it minimizes overstocking and understocking, and contributes to a more efficient ordering process.
1. Introduction
The shrinking workforce is an urgent issue in the retail industry, which relies heavily on part-time and temporary help. In a situation where decreasing manpower can directly result in a reduction in business, we believe that the demand for labor-saving systems and automatization will skyrocket along with the search for new sources of manpower.
Among the daily tasks that workers find difficult to master in a short amount of time is "ordering." Automatic ordering systems are being put into place for non-perishables (such as groceries with long shelf lives and sundries), where mistakes in ordering do not have a critical impact on business. However for Fresh Food (groceries with short shelf lives) the cost of disposing misordered goods can have a direct impact on business performance; and since sales of these items is influenced by environmental factors such as the weather, sales campaigns and local events, the implementation of automatic ordering was considered extremely difficult.
In this paper, we will explain about Predictive Analytics Solution for Fresh Food Demand (Fig. 1), which is a demand-predictive automatic ordering solution for Fresh Food goods based on NEC's original machine learning algorithm called "heterogeneous mixture learning technology."
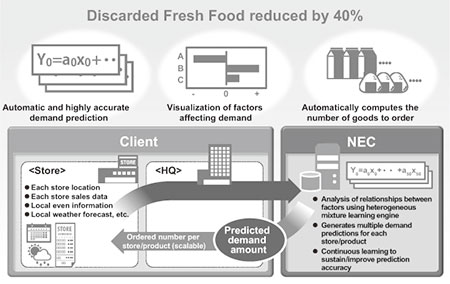
2. Solution Characteristics
2.1 Algorithm Characteristics
The two factors as listed below comprise the main characteristics of heterogeneous mixture learning technology.
(1) Automatically finds the optimal pattern
In order to accurately predict the demand of Fresh Food, it is critical to first create a model that incorporates the various retail environment factors for the store. We will explain how important it is to take environmental differences into consideration by using a convenience store as an example.
When you compare a regular convenience store facing a surface street, with a convenience store inside an office building, their sales trends will differ. When there is rain, chances are that customers and sales will drop in the case of a regular street-level store. By contrast, sales tend to rise in the case of a store located inside an office building since the number of office workers going outside the building would drop as more people choose to stay in and perhaps buy lunch at the convenience store. As you can see, even when faced with identical environmental conditions (i.e. rain) sales may trend differently depending on the location of the store.
In order to reflect this difference within the prediction model, it is necessary to develop individual prediction models that are specific to each store. For vast chain-operated businesses like supermarket and convenience store chains, the amount of calculation necessary would literally require a supercomputer, making it impossible to realize using conventional technology. However, by using heterogeneous mixture learning technology, it becomes possible to develop optimal prediction models automatically, based on a realistically feasible amount of calculation.
(2) Prediction model with high readability
One critical factor when predicting demand is whether it is possible to comprehend the root causes that led to the computed result. Since no prediction can offer 100% accuracy, it is extremely important to be able to understand the reasons why a prediction missed its mark.
For example, a prediction model typically uses the local weather forecast as the source of weather information. And since weather forecasts are not 100% accurate, we need to take into consideration that prediction accuracy can be undermined by an inaccurate weather forecast. On the other hand, if the prediction is inaccurate due to some problem with the prediction model itself, this would require immediate corrective action. In order to differentiate between these two, the sustainability of the prediction model becomes a major issue.
Another item that requires consideration is the acquisition of data and how it relates to prediction accuracy. When making predictions, it is often the case that using more types of data will yield better results, regardless of whether they are actually implemented in the prediction model itself or not. However, if due consideration is not given to the cost associated with acquiring the data, as well as the work involved in managing the data, the sustainability of the model may be jeopardized.
Let us illustrate this point by using the prediction for a retail store near an event venue as an example. In order to incorporate event details into the prediction model, we would have to gather copious amounts of information - things like whether the upcoming event is an exhibition or a concert, if it is an exhibition then what sort of visitor profile do we expect, or if it's a concert then who is performing, what is he playing, and how well are tickets selling. In view of the cost and effort involved, it is best to avoid needing to acquire such information on a daily basis.
When the prediction model offers high readability, it is possible to develop the initial prediction model based on all factors considered relevant, then narrowing the data down to the key factors that affect the model the most to continue with the predictions. Doing so reduces the burden of data acquisition and leads to improved sustainability.
2.2 Application Function Characteristics
With conventional automatic ordering applications, it was necessary to input data and prioritize each parameter (tuning) each time. But with NEC's solution, demand predictions are computed without having to manually input any parameters, plus it even generates product orders automatically based on the demand predictions in conjunction with store inventory and delivery schedule information.
Unlike conventional automatic ordering applications that require experienced staff to take care of the tuning process, NEC's solution can be implemented automatically, thereby helping to reduce the manpower requirement while increasing the stability and accuracy of orders.
Another feature of the application function is that when placing orders it is possible to set Preferences. Unlike tuning, which is objective in nature, the Preferences feature enables a store to subjectively modify the volume of an order - such as when a store increases an order as a matter of policy, to maintain a full shelf of this or that particular product category at all times. Of course this type of aggressive ordering, where ample stock is maintained at the expense of a few extra discards, can be accommodated by the simple ability to increase the order in increments of 10. But it also stands to reason that the increased amount on a sunny day should be different from a rainy day, and that the ability to modify the values for each store or product more flexibly would lead to more effective enforcement of store policy.
3. Solution Effects
3.1 In-store Effects
On-site verification at stores showed that we were able to reduce disposed items by approx. 40% compared to the personnel in charge of ordering until then. For some categories, although disposal loss was not dramatically reduced, the store inventory was increased, so that in effect, sales increased.
In the conventional ordering process that relies on a mixture of hunch, experience and sentiment, when a person makes the mistake of ordering too many goods, he then tends to overcompensate the next time by ordering too few. As a result, the product will run out of stock and a sales opportunity will be missed. But when NEC's system computes the orders, it will do so free of any such psychological bias, thereby delivering positive results as mentioned above.
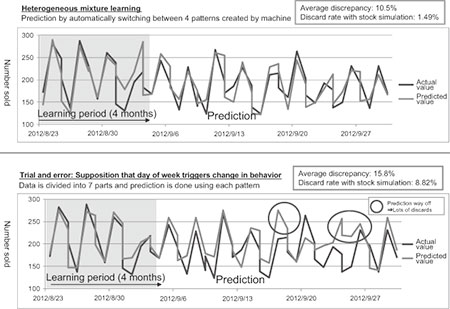
Other contributing factors include the ability to stay on top of daily demand without missing the mark in any major way. Comparing our results with those yielded by a conventional statistical algorithm tuned by a data scientist (Fig. 2), we can see that the difference in the disposal rate is more pronounced than the statistical difference in the prediction would indicate. This is because heterogeneous mixture learning technology produces prediction results that are not far off the mark; so that even if some excessive inventory is accumulated, this slack can easily be taken up by reducing the volume of the next order.
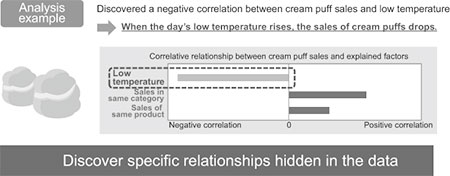
We also found positive results stemming from the prediction model's high readability. Let us explain using the demand prediction results for cream puffs (Fig. 3) at a certain store. Sales for cream puffs and other sweets characterized by their rich taste of custard cream tend to drop as the temperature becomes warmer. Up until now, sharing know-how was done using printed manuals. But since this would make it nearly impossible to have manuals customized for each store that prescribed how much sales are expected to increase with a 1 degree drop in temperature, ordering was largely reliant on the skill level of the person placing the order. When the model offers high readability, contributing factors such as these can be readily understood, making the model feasible in areas other than ordering, such as product development.
3.2 Prediction at New Stores
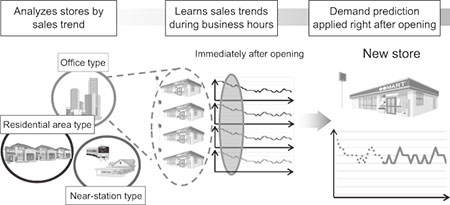
Since machine learning technology uses data from the past to learn and predict the future, what should be done in cases where past data has not been accumulated, such as demand prediction for newly opened stores, became a major issue. Especially in business categories such as convenience stores, where new stores open every month, the demand prediction capability for new stores is a prime concern.
NEC's solution is capable of predicting demand for newly opened stores by learning the collective sales data of multiple stores that were similar to the new store at the time of their opening (Fig. 4). We actually found that in the case of new stores with only sparse amounts of accumulated original data, the prediction results based on data from other stores proved to be more accurate than those based on the new store's own data. By applying this same method, it will be possible to predict sales figures for new stores, as well as sales of new products even before they actually hit the shelves.
4. Conclusion
In May of 2015, the French legislature passed a law that prohibits the discarding of expired foodstuffs by large-scale supermarkets. In view of the worldwide food shortage that many believe is impending, nations throughout Europe and the Americas have begun discussions on how to address the problem of food waste.
By realizing demand prediction at retail stores, which is the part of the distribution channel that comes into closest contact with the customer, it will be possible to reduce the disposal loss associated with preparing ready-to-eat items and boxed lunches, as well as the over-procurement of ingredients needed to prepare them.
We believe that NEC's solution will prove effective not only in boosting the efficiency and accuracy of the ordering process, but also in coping with the problem of food waste through its application over the entire SCM (Supply Chain Management).
Authors' Profiles
OCHIAI Kotaro
Manager
Global Retail Solutions Division
Manager
Global Retail Solutions Division