Global Site
Displaying present location in the site.
vrAIn: Deep Learning based Orchestration for Computing and Radio Resources in vRANs
Vol.17 No.1 September 2023 Special Issue on Open Network Technologies — Network Technologies and Advanced Solutions at the Heart of an Open and Green Society PDF
PDFWe present vrAIn, a resource orchestrator for vRANs based on deep reinforcement learning. First, we use an autoencoder to project high-dimensional context data into a latent representation. Then, we use a deep deterministic policy gradient (DDPG) algorithm based on an actor-critic neural network structure and a classifier to map contexts into resource control decisions. Our results show that: (i) vrAIn provides savings in computing capacity of up to 30% over CPU-agnostic methods; (ii) it improves the probability of meeting QoS targets by 25% over static policies; (iii) upon computing capacity under-provisioning, vrAIn improves throughput by 25% over state-of-the-art schemes; and (iv) it performs close to an optimal offline oracle.
1. Introduction
Radio Access Network virtualization (vRAN) is well- recognized as a key technology to accommodate the ever- increasing demand for mobile services at an affordable cost for mobile operators. vRAN centralizes softwarized radio access point (RAP)* stacks into computing infrastructure in a cloud location — typically at the edge, where CPU resources may be scarce. Fig. 1 illustrates a set of vRAPs sharing a common pool of CPUs to perform radio processing tasks such as signal modulation and encoding (red arrows). This provides several advantages, such as resource pooling (via centralization), simpler update roll-ups (via softwarization) and cheaper management and control (via commoditization).
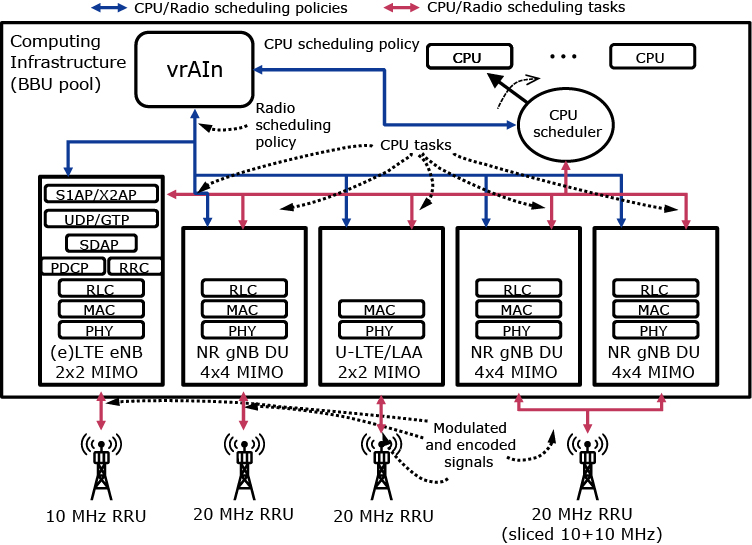
It is thus not surprising that vRAN has attracted the attention of academia and industry. O-RAN or Rakuten Mobile’s vRAN — led by key operators (such as AT&T, Ver- izon or China Mobile), manufacturers (such as Intel, Cisco or NEC) and research leaders (such as Standford University) — are examples of publicly disseminated initiatives towards fully programmable, virtualized and open RAN solutions based on general-purpose processing platforms and decoupled base band units (BBUs) and remote radio units (RRUs).
Despite the above, the gains attainable today by vRAN are far from optimal, and this hinders its deployment at scale. In particular, computing resources are inefficiently pooled since most implementations over-dimension computational capacity to cope with peak demands in real-time workloads.
Dynamic resource allocation in vRAN is an inherently hard problem:
- (1)The computational behavior of vRAPs depends on many factors, including the radio channel conditions or users’ load demand, that may not be controllable. More specifically, there is a strong dependency with the context (such as data bit-rate load and signal-to- noise-ratio (SNR) patterns), the RAP configuration (e.g., bandwidth, MIMO setting, etc.) and on the infrastructure pooling computing resources.
- (2)Upon shortage of computing capacity (e.g., with nodes temporarily overloaded due to orchestration decisions) CPU control decisions and radio control decisions (such as scheduling and modulation and coding scheme (MCS) selection) are coupled.
We present vrAIn, an artificial intelligence-powered (AI) vRAN orchestrator that governs the allocation of computing and radio resources (blue arrows in Fig. 1).
- *The literature uses different names to refer to different radio stacks, such as base station (BS), eNodeB (eNB), gNodeB (gNB), access point (AP), etc. We will use RAP consistently to generalize the concept. made to the content, wording, positioning, priority, and emphasis of the constituent elements.
2. vrAIn design
The vRAN landscape powered by vrAIn (Fig. 1) consists of a feedback control loop where:
- (1)Contextual information (SNR and data load patterns) is collected and encoded.
- (2)An orchestrator that maps contexts into computing and radio scheduling policies.
- (3)A reward signal assesses the decisions taken and fine- tunes the orchestrator accordingly.
We hence formulate our resource control problem as a contextual bandit (CB) problem, a sequential decision-making problem where, at every time stage n∈N, an agent observes a context or feature vector drawn from an arbitrary feature space x(n), chooses an action a(n) and receives a reward signal r(x(n), a(n)) as feedback.
Context Space: At each stage, T context samples are collected. Each sample consists of the buffer size, the mean SNR, and the variance SNR, measured for all users across all vRAPs.
Action Space: Our action space comprises all pairs of CPU and radio scheduling policies. ![]() and
and ![]() denote, respectively, the maximum computing time share (CPU scheduling policy) and the maximum MCS (radio scheduling policy) allowed to vRAP i in stage n. We also let
denote, respectively, the maximum computing time share (CPU scheduling policy) and the maximum MCS (radio scheduling policy) allowed to vRAP i in stage n. We also let ![]() denote the amount of CPU resource left unallocated (to save costs). Thus, a resource allocation action on vRAP i consists of a pair ai:= {ci,mi} and a system action
denote the amount of CPU resource left unallocated (to save costs). Thus, a resource allocation action on vRAP i consists of a pair ai:= {ci,mi} and a system action ![]() .
.
Reward: The objective in the design of vrAIn is twofold:
- (1)When the CPU capacity is sufficient, the goal is to minimize the operation cost (in terms of CPU usage) as long as vRAPs meet the desired performance.
- (2)When there is a deficit of computing capacity to meet such performance target, the aim is to avoid decoding errors that lead to resource wastage, thereby maximizing throughput and minimizing delay.
To meet this objective, we design the reward function as follows. Let qi,xi,ai be the (random) variable capturing the aggregate buffer occupancy across all users of vRAPi given context xi and action ai at any given slot. As a quality-of-service (QoS) criterion, we set a target buffer size Qi for each vRAP. Note that this criterion is closely related to the latency experienced by end-users (low buffer occupancy yields small latency) and throughput (a high throughput keeps buffer occupancy low). Thus, by setting Qi, an operator can choose the desired QoS, which can be used to, e.g., provide differentiation across network slices. We let ![]() be the probability that qi,xi,ai is below the target per vRAPi and define reward as:
be the probability that qi,xi,ai is below the target per vRAPi and define reward as:
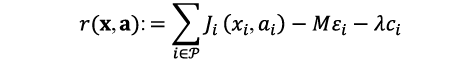
where εi is the decoding error probability of vRAPi (which can be measured locally), and M and λ are parameters that determine the weight of decoding errors and the trade-off between resource usage and performance, respectively. We set M to a large value to avoid decoding errors due to low allocations and λ to a small value to meet QoS requirements (while minimizing the use of compute resources).
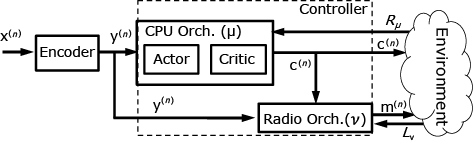
To solve our CB problem, we design the system depicted in Fig. 2. First, we encode each context x(n) into a latent representation using Sparse Autoencoders (SAE), which yield a lower-dimensional vector y(n). Then, we decouple both action policies into two orchestrators: CPU orchestrator and Radio orchestrator. We build the radio orchestrator as a simple classifier v that, given an encoded context y(n), provides the maximum MCS that can be processed reliably given computing resource policy c(n). Conversely, we design our CPU orchestrator with a deep deterministic policy gradient (DDPG) algorithm using a model-free actor-critic neural network structure as shown in the figure.
3. Evaluation
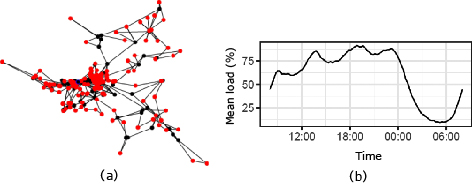
To assess the performance attained by vrAIn in a real-world scenario, we simulate vrAIn over a production RAN deployment in a European city, with 197 access points distributed as shown in Fig. 3 (a). As we can observe from the figure, there is a higher density of RAPs in the center (a big city) and the RAN is sparser by the outskirts (covering mostly highways and small commuter suburbs). In order to leverage our training data, and without loss in generality, we assume all RAPs are SISO 10-MHz LTE vRAPs with the same behavior as our LTE vRAPs analyzed in Section 1.
Our custom-built simulator follows the 3GPP guidelines for LTE performance evaluation and its parameters are detailed in Table. The Signal-to-interference-plus-noise-ratio (SINR) perceived by the UEs is obtained by aggregating the interference of all active RAPs. For a given SINR, we compute the CQI of this UE, and then the maximum allowed MCS associated with this CQI according to 3GPP specification. Further, we implement a random mobility model for the UEs, ensuring a minimum distance between UE and RAP of 35 m, as recommended by 3GPP. Finally, due to the difficulty to capture the computing behavior of our vRAPs in a tractable model for simulation, we have implemented a deep neural network (DNN), trained using our dataset, to determine when decoding errors occur due to lack of computing resources.
Table Simulation parameters.
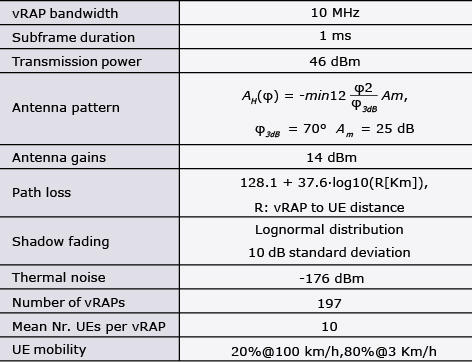
We simulate one regular week using synthetic traffic patterns, which emulate the behavior of real RANs at scale. To simplify the analysis, in the following we focus on a 24-hour period during weekdays — with the traffic profile (relative to the capacity of the system) shown in Fig 3 (b). We further assume that the aggregate computing capacity of the whole vRAN is dimensioned to the minimum amount of CPU resources required such that no violations of the encoding deadlines due to CPU deficit occur during the load peak of the day when not using vrAIn, which we refer to as “100% provisioning”. We also study the behavior of vrAIn when the system is under-provisioned to 70% and 85% of that computing capacity, which enables capital cost savings.
3.1 Provisioning computing capacity for the peak
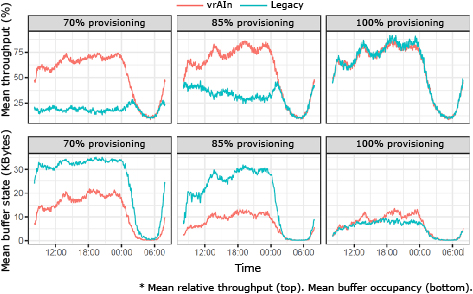
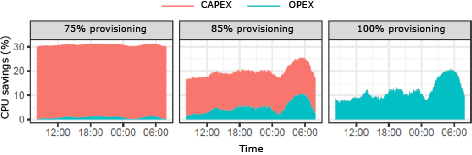
Let us first focus on the evolution of throughput performance, buffer states and cost savings when the computing capacity is provisioned to accommodate the peak load (right-most plots in Fig. 4 and Fig. 5 labeled as “100% provisioning”). From Fig. 4 we observe that vrAIn achieves roughly the same throughput performance and slightly higher buffer sizes (up to 5%) than “Legacy”. This is explained because vrAIn trades off this slightly higher delay for substantial OPEX savings. This is shown in Fig. 5 (right-most plot, labeled as “100% provisioning”), where vrAIn achieves between 10% and 20% of OPEX savings. Note however that this difference in delay vanishes when vrAIn is configured to favor performance over OPEX savings (results omitted here for the sake of space).
3.2 Under-provisioning of computing capacity
We now analyze the case where we impose under-provisioning to obtain aggressive CAPEX gains by reducing the availability of computing capacity to 85% and 70% relative to the dimensioning strategy discussed before, and labeled as “85% provisioning” and “70% provisioning”, respectively, in Fig. 4 and Fig. 5. The evolution of throughput and buffer states in Fig. 4 for these two scenarios (left-most and middle plot, respectively) make it evident how vrAIn enables aggressive CAPEX savings while retaining high performance gains when compared to legacy computing-agnostic approaches. Specifically, vrAIn provides up to and throughput gains over our legacy scheme when, respectively, the computing capacity is under-provisioned to 85% and 70% of the peak load, in average, and during the time of peak demand (between 18:00 and 00:00). The reason lies on the fact that vrAIn’s ability to optimize jointly radio and computing scheduling policies allows vrAIn to better accommodate the demand along the time domain, trading off delay for near-zero violations of the encoding deadlines due to a deficit of computing capacity. In contrast, legacy’s agnostic behavior with respect to the availability of computing capacity yields substantial throughput loss due to a high rate of violations of the encoding deadlines during instantaneous peak demands. This produces a cascade effect causing large amounts of time wasted in re-transmissions and rendering even larger perceived latency: up to and higher buffer occupancy over vrAIn for 85% and 70% of computing provisioning, respectively, in average, and in the same period of peak demand.
A final remark is that vrAIn adapts, i.e., maximizes performance, to constrained computing environments. This can be observed by comparing the performance indicators of both “70% provisioning” and “85% provisioning” to those shown for “100% provisioning”. In particular, vrAIn has no loss in throughput performance for “85% provisioning” and only up to 10% throughput loss for “70% provisioning”, in average, and during the same period of peak demand discussed earlier. This contrasts with the substantial throughput loss attained by our legacy approach: up to 65% and 80% of throughput loss in those same conditions. In terms of latency, vrAIn only suffers from 1% increased in mean buffer occupancy in the case of “85% provisioning” relative to the buffer occupancy for “100% provisioning” (in contrast to the 282% increase of the legacy approach), and 73% increased in mean buffer occupancy with 75% under-provisioning (in contrast to the 337% increase of the legacy approach).
- *Intel and the Intel logo are trademarks of Intel Corporation or its subsidiaries.
- *Cisco, Cisco Systems, and the Cisco logo are trademarks or registered trademarks of Cisco Systems, Inc. in the United States and other countries.
- *The names O-RAN ALLIANCE, O-RAN and their logo are trademarks or registered marks of O-RAN ALLIANCE e.V.
- *Rakuten Mobile is a trademark of Rakuten Group, Inc. or its affiliates.
- *All other company names and product names that appear in this paper are trademarks or registered trademarks of their respective companies.
Authors’ Profiles
AYALA-ROMERO Jose
Senior Researcher
6G Networks
NEC Laboratories Europe
Senior Researcher
6G Networks
NEC Laboratories Europe
GARCIA-SAAVEDRA Andres
Principal Research Scientist
6G Networks
NEC Laboratories Europe
Principal Research Scientist
6G Networks
NEC Laboratories Europe
COSTA PEREZ Xavier
Manager
6G Networks
NEC Laboratories Europe
Manager
6G Networks
NEC Laboratories Europe

