Global Site
Displaying present location in the site.
Intention Learning Technology Imitates the Expert Decision-Making Process
Artificial intelligence (AI) is now being used to automate a wide range of tasks. Typically, automation is achieved by setting optimization indices for the levels of acceptability or unacceptability in target tasks and having the AI automatically search for the decision that maximizes or minimizes those indices (optimal solutions in mathematical optimization) as required. However, with tasks that require a certain level of skill and expertise — what we might call “expert-dependent” tasks — setting optimization indices is more difficult, making these tasks harder to automate. This paper introduces NEC’s intention learning technology which learns intentions from the decision-making history data of various experts. These intentions can be used as optimization indices, enabling the AI to imitate the decision-making processes of experts in the task being automated and making it possible to automate tasks that would normally require a human expert to accomplish.
1. Introduction
Artificial intelligence (AI) today plays a crucial role in the automation of a broad array of tasks. The first step in automating any given task is to set indices for the levels of acceptability or unacceptability (optimization indices). The AI automatically searches for the decision that maximizes or minimizes those indices (optimal solutions in mathematical optimization) as required. For example, when developing a marketing campaign, you would first set cost-effectiveness as an optimization index; the AI would then search for the campaign that best realizes this goal and determine at whom it should be targeted. However, setting an optimization index for tasks that depend heavily on specialized human expertise and know-how — expert-dependent tasks — is more difficult. You often have to work closely with experts to determine what should be used for optimization indices and how much emphasis should be put on them. This process involves repeated A/B testing, and consumes immense amounts of time and money, rendering it largely impractical.
To address this issue, NEC has developed intention learning technology. This technology uses the decision-making history data of multiple experts, gleaning from this the “intention” that drives the decisions as shown in Fig. 1. By executing mathematical optimization on the learned optimization indices, AI can imitate the decision making of experts, enabling the automation of even expert-dependent tasks. Intention learning technology is based on inverse reinforcement learning (IRL)1). Its two main features are:
- 1)Modeling complex intentions as interpretable optimization indices
- 2)Significant improvement in computation efficiency compared to conventional IRL
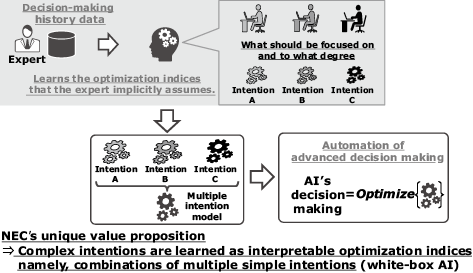
When an expert makes a decision, the intentions or objectives that underlie that decision are many and complex. In order to automate that process, these intentions must be learned as complex optimization indices. With conventional IRL, this is achieved by modeling using complex neural networks. NEC’s intention learning technology, on the other hand, models complex intentions as combinations of multiple simple intentions (linear forms). This allows you to explicitly understand what should be focused on in what situations and to what degree. This further assures the interpretability required for practical applications. Although the IRL is essentially an algorithm with a high computational cost, we have developed a method that significantly increases computational efficiency and makes this technology more suitable for practical use. In the following sections, we will review descriptions of intentions in mathematical optimization problems, explain the features of intention learning technology, and provide some examples of practical applications.
1.1 Intentions in mathematical optimization problems
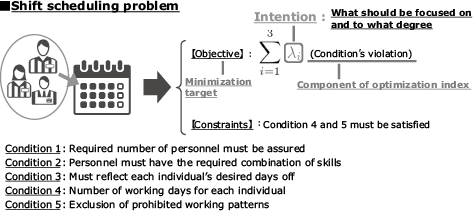
First, let’s examine “intention” as it applies to a mathematical optimization problem. In the following example, we show how this would be used to deal with a shift scheduling problem in a retail store. This problem can be handled as a combinatorial optimization problem. The optimal solution is found by searching the schedule for a solution that satisfies the following conditions:
- Condition 1: Required number of personnel must be assured.
- Condition 2: Personnel must have the required combination of skills.
- Condition 3: Must reflect each individual’s desired days off.
- Condition 4: Number of working days for each individual.
- Condition 5: Exclusion of prohibited working patterns.
Conditions 4 and 5 must always be satisfied while conditions 1, 2, and 3 can be violated to some extent. Based on this, conditions 4 and 5 are set as fixed constraints. Schedules (combinations) that minimize the weighted sums (i.e., objective functions) of the violation levels of conditions 1, 2, and 3 are determined to be optimal solutions.
The weights of the components of these optimization indices represent intentions for what should be focused on and to what degree. In the shift scheduling problem as shown in Fig. 2, the intentions correspond to what should be focused on and to what degree in conditions 1, 2, and 3. In this manner, the intention in a mathematical optimization problem in the intention learning technology refers to the weight of each component of an optimization index.
2. Intention Learning Technology
In intention learning technology, IRL — the foundation for intention learning technology — is expanded. The two main features of intention learning technology are:
- 1)Modeling complex intentions as interpretable optimization indices
- 2)Significant improvement in computation efficiency compared to conventional IRL
Before looking at the two main features of intention learning technology, we will summarize the basics of IRL.
2.1 IRL: The Foundation of Intention Learning
IRL is a method to solve inverse problems of reinforcement learning. While in reinforcement learning an optimal solution is searched from optimization indices set in advance, in IRL decision-making histories of experts are assumed to be optimal solutions and their optimization indices are therefore learned. Additionally, IRL can not only handle reinforcement learning but also inverse problems of various mathematical optimization problems such as combinatorial optimization and optimal control. Input items in IRL algorithms include: (1) decision-making history data of experts, (2) optimization solvers for mathematical optimization problems (combinatorial optimization, optimal control, or reinforcement learning) corresponding to the automation target task, and (3) respective components of optimization indices and initial weight values, as shown in Fig. 3. The system alternates between searching for an optimal solution (decision-making history) based on an optimization index and updating the weight of the optimization index in order to minimize the difference between the optimal solution and the expert’s decision-making history. Once the optimal solution closely approximates the expert’s decision-making history, learning is complete and an optimization index now that matches the expert’s decision is output.
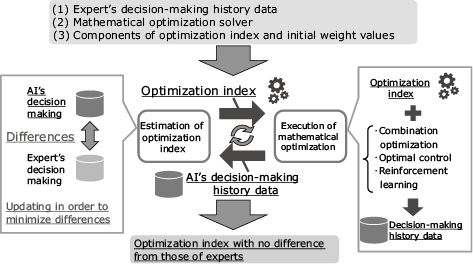
The two main issues affecting practical use of IRL are how to model a complex intention in an interpretable form and how to reduce the high computational cost that comes from having to repeatedly execute mathematical optimization inside the algorithm.
2.2 Feature 1: Modeling complex intentions in an interpretable form
Conventional IRL learns experts’ complex intentions as single optimization indices. When modeled in linear form with high interpretability, this results in a lack of expressiveness. If you want high expressiveness, you have to model the intentions in neural networks, thereby sacrificing interpretability. Simply put, it has so far proven virtually impossible to achieve compatibility between interpretability and expressiveness, which is essential for modeling complex intentions. NEC’s intention learning technology was developed to solve this problem. Using heterogeneous mixture learning2) — one of the cutting-edge AI technologies that make up NEC the WISE — to expand IRL, intention learning technology is able to learn multiple linear forms and their switching rules from expert decision-making history data as optimization indices. This makes it possible to express complex intentions as combinations of multiple simple intentions and to model them as interpretable optimization indices that allows you to explicitly understand what should be focused on and to what degree and in what situation (Fig. 4).
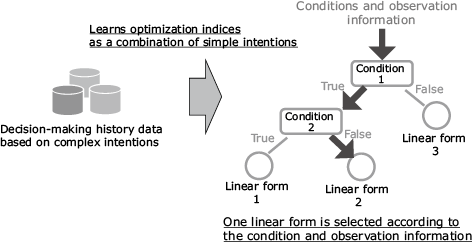
2.3 Feature 2: Improved computational efficiency of learning algorithms
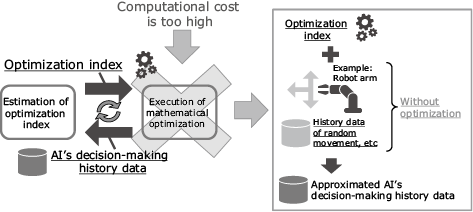
In general, IRL alternately performs searches for optimal solutions based on optimization indices (decision-making history) and updates the weights of the optimization indices in order to minimize the differences from the experts’ decision-making histories. The computational cost of repeatedly executing mathematical optimization processes inside the algorithm is enormous, making it critical that a way be found to reduce that cost. NEC’s intention learning technology addresses this issue by utilizing newly added non-optimal decision-making history data (based on random measures, for example). Specifically, it performs an approximate computation based on the new data with information about what kind of optimal solutions the present optimization indices will bring. This makes it unnecessary to execute mathematical optimization inside learning algorithms as shown in Fig. 5, achieving a substantial reduction in computational cost compared to conventional IRL.
3. Application Example: TV Advertisement Scheduling
Scheduling advertising at a TV station requires optimal allocation of multiple TV commercials to limited program time slots while considering the effectiveness of the advertisement and the preference of the sponsor3). Possible optimization indices include a deployable remaining time count (maximization problem: OR1) to maximally take advantage of the time slot and a surplus amount exceeding the required viewer rating (minimization problem: OR2). However, these indices cannot respond to more specific requirements such as the need to air commercials for health food and supplements early in the morning or in the afternoon when the elderly are likely to watch TV. Gathering data regarding a broadcast strategy for each commercial is extraordinarily time-consuming, making automation of this task virtually impossible.
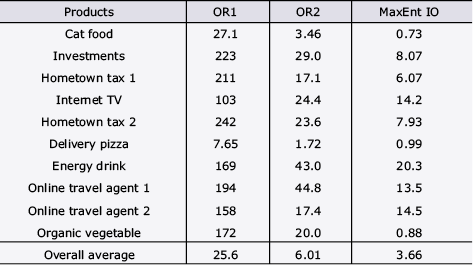
To apply intention learning technology to this TV commercial scheduling task, we used previous broadcast schedules as expert decision-making history data. As components of optimization indices, we set deployable a remaining time count and viewer rating that could be obtained at each time slot. As a constraint, we made a setting so that the viewer rating required for each commercial would be satisfied. Table shows a comparison of the magnitude of differences (cosine distance [×10−7]) between the actual TV advertisement scheduling and the schedule produced by the intention learning technology (MaxEnt IO) and mathematical optimization without learned functions (OR1, OR2). The results make clear that intention learning technology was more capable of imitating expert decision making than the two other methods.
Table Differences in actual TV advertisement scheduling according to different method
4. Conclusion
NEC’s intention learning technology promises to be a valuable solution to the problem of automating expert-dependent tasks, which until now has proven extremely difficult. By learning optimization indices as intentions based on the decision-making history data of various experts, this technology can make proposals that closely resemble the actual decisions that an expert would make as the TV commercial scheduling example makes clear. As AI automation becomes increasingly important in countries with shrinking workforces and decreasing populations, NEC’s intention learning technology can benefit society by helping automate those tasks where it is difficult to pass on the expertise and skills of experts.
References
- 1) Saurabh Arora, and Prashant Doshi: A Survey of Inverse Reinforcement Learning: Challenges, Methods and Progress, arXiv:1806.06877, 2018
- 2) Riki Eto, Ryohei Fujimaki, Satoshi Morinaga, and Hiroshi Tamano: Fully-Automatic Bayesian Piecewise Sparse Linear Models, Proceedings of the 17th International Conference on Artificial Intelligence and Statistics (AISTATS), 2014
- 3) Yasuhisa Suzuki, Wemer M. Wee, and Itaru Nishioka: TV Advertisement Scheduling by Learning Expert Intentions, KDD 2019, 2019
Authors’ Profiles
ETO Riki
Senior Researcher
Data Science Research Laboratories
Senior Researcher
Data Science Research Laboratories
SUZUKI Yasuhisa
Data Science Research Laboratories
Data Science Research Laboratories
NAKAGUCHI Yuki
Data Science Research Laboratories
Data Science Research Laboratories
KUBOTA Dai
Data Science Research Laboratories
Data Science Research Laboratories
KASHITANI Atsushi
Senior Expert
Data Science Research Laboratories
Senior Expert
Data Science Research Laboratories