Global Site
Displaying present location in the site.
New Logical Thinking AI Can Help Optimize Social Infrastructure Management
NEC is now working on new artificial intelligence (AI) technology for industrial plant operation support that combines logical reasoning with knowledge, enabling it to qualitatively infer how the plant operates by drawing on information contained in operating manuals and design information. Reinforcement learning that incorporates a plant simulator that is used to train the system, making it possible for it to learn optimal operation of a complex plant in a realistic time frame. This paper provides a general overview of this technology and examines the validation results produced using a chemical plant simulator.
1. Introduction
In many industrial plants today — such as chemical plants and power plants — operations are almost fully automated. Nevertheless, the need for manual intervention remains — for instance, when the plant is started up, when something breaks down, when specifications are changed, when the plant is shut down, or when any other irregular situation occurs. Due to the complexities and magnitude of the potential consequences, which, in some cases, can impact surrounding communities and social infrastructure, these operations often depend on skilled and experienced operators. With the availability of such personnel expected to decline in coming years as older workers retire without being replaced, industries are increasingly looking to AI to provide support for those operations.
2. Issues Impacting the Application of AI
Research and development into reinforcement learning has been moving forward rapidly in recent years with a view to using it to teach AI operating procedures. Reinforcement learning enables the AI agent to learn the optimal operation in order to maximize the reward function that indicates the optimal operating condition by collecting data as the AI interacts with a simulated environment. While effective in a limited environment, applying this method in a large-scale plant means that you need to take into account the fact that there are many control points in the plant, and that each of them has to be given continuous values as control variables. Because this makes the scope of the search necessary to gather learning data so enormous, actually completing the learning in a reasonable time frame is nearly impossible. Another drawback of conventional reinforcement learning is that it doesn’t tell you why it has decided to perform an operation. This kind of black-box AI does not satisfy the critical need for accountability in the management of facilities — such as chemical plants or power — where an error could potentially lead to catastrophic consequences for surrounding communities, further hindering the deployment of AI.
3. Logical Thinking AI
To solve the dual problem of slow learning and unaccountability, NEC developed a logical thinking AI that integrates logic and data to quickly learn appropriate procedures and provide the reasoning behind its solutions. Fig. 1 illustrates an overview of logical thinking AI. Logical thinking AI derives operating procedures in two layers. First, to narrow down candidates for operating procedures, it uses logical reasoning based on information about the plant’s designs and piping configuration, as well as any other available knowledge sources such as operating manuals. Next, using reinforcement learning and a plant simulator, it tests the selected procedures and determines details of how the operation will proceed. Using logical reasoning makes it possible to limit the scope of the search, enabling the AI to learn optimal procedures in a reasonable time frame. Because logical reasoning itself is guided by information that can be understood by human operators such as manuals and design information, it can present a clear rationale for its recommendations, enabling human operators to understand and execute the suggested operation procedure. We will discuss the component technologies of the logical thinking AI in more detail below.
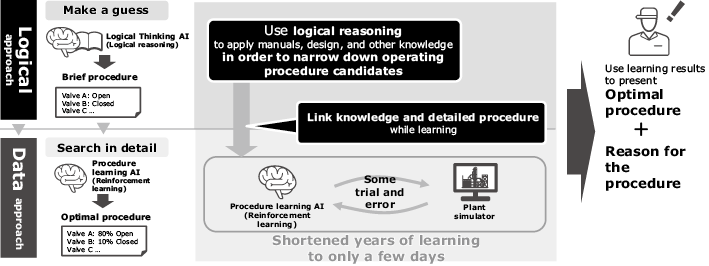
3.1 Logical reasoning
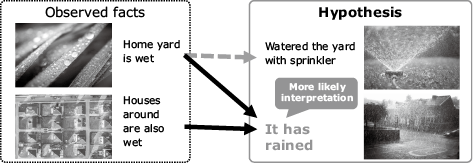
Logical reasoning technology compares observed facts with learned knowledge to infer the most valid hypothesis as an explanation. Fig. 2 shows an example of the reasoning that leads to a hypothesis. In this example, the line of reasoning is as follows: When you see that the grass in your front yard is wet on a sunny morning, your first thought might be that the sprinkler was on very early in the morning and watered the lawn. However, when you look around, you see that your neighbors’ lawns are also wet. Thus, the logical conclusion is that it rained overnight, rather than that the sprinkler operated early in the morning. In this way, logical reasoning can deduce plausible results from given facts — in other words, it lets you infer an interpretation. You can also put it this way: The machine is doing the same thing experienced people do when they draw on their knowledge to quickly infer what is currently happening.
The same type of reasoning can be applied to the operation of an industrial plant (Fig, 3). Narrowing down suitable operating procedures means the attainment of goal conditions where the temperature and pressure are set at the rated values from the currently observed conditions. Some manuals define these as a series of procedures. Depending on the conditions, however, a solution is not possible unless multiple procedures are combined. Logical reasoning retains many pairs of operations and conditional variations as knowledges (circled in a dotted line). For example, the AI knows that when pressure valve A is opened, pressure B drops as shown in the chart. By connecting those pairs, it searches for a combination that can reach the goal conditions.
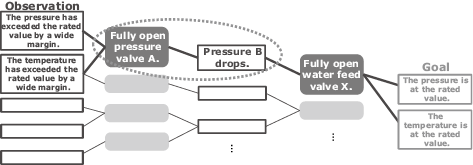
In this way, logical reasoning examines plant actions on a qualitative basis to infer operating procedures. However, on its own this is insufficient to determine the extent of operation required. For example, even though the AI knows that the pressure valve should be opened, it does not know how much it should be opened and for how long. With logical thinking AI, qualitative operations can be determined by combining deductive reasoning with reinforcement learning.
3.2 Reinforcement learning
Reinforcement learning is a machine learning method that learns functions that determine what actions should be taken (policy functions). A software agent runs in a simulated environment and observes present states (Fig. 4). The agent acts on the environment, accumulating experience and learning through trial and error. It learns policy functions to maximize the accumulated value of rewards obtained as the result of an action. By using a simulator for the environment, the AI can learn optimal operations under a variety of difficult states that are difficult to try in actual plants. Since optimal actions are learned by trial and error in reinforcement learning, the scope of the search expands explosively as the dimensions of actions (numbers of operation points) increase, greatly extending the learning time required until high rewards are obtained. The logical thinking AI uses logical reasoning to narrow down the search to limited set of actions that can be taken. As a result, learning is now possible in a reasonable time frame.

4. Validation with a Chemical Plant Simulator
In order to verify the effectiveness of the logical thinking AI, we conducted a validation test using a chemical plant simulator for benchmarking1).
4.1 Plant simulator
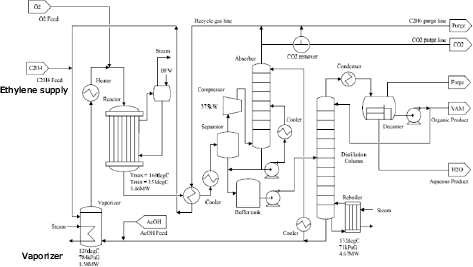
The plant simulator we used is a vinyl acetate monomer (VAM) manufacturing plant simulator. This simulator is a benchmark simulator intended for optimization of operations in a chemical plant. It is built and distributed by the Process System Engineering 143 Committee2)3). In the simulated plant, a synthetic reaction that generates VAM and water is performed with the input of ethylene gas, acetic acid, and oxygen to separate VAM. The plant has 107 sensors, 45 proportional integral derivative (PID) controllers, and 31 valves. The simulator reproduces all plant operations, including mixing raw materials, reaction, separation, and recycling (Fig. 5).
4.2 Validation tasks
To train the agent, the simulator artificially generates disruptions and failures. In the validation test we conducted, we generated a disruption — fluctuations in the supply pressure of ethylene gas — to verify whether or not the simulator would be able to derive an appropriate response. When the supply pressure of ethylene fluctuates, the pressure of the vaporizer that mixes the raw materials also fluctuates, making it impossible to attain appropriate reaction conditions. As a result, the product specifications (VAM) cannot be met, hence creating production loss. Therefore, it is necessary to avoid production loss by restoring the rated value of the vaporizer’s pressure as soon as possible.
When we had the simulator try to learn the appropriate countermeasure using proximal policy optimization (PPO)4) — a popular reinforcement learning method, the simulator could not complete the learning because there were 31 valves to be operated, which necessitated an enormous number of trial-and-error simulations.
4.3 Deriving a countermeasure using logical thinking AI
Using logical reasoning, the logical thinking AI first identifies the valve to be operated drawing on the information provided in the operating manual and piping diagram included with the simulator. Using logical reasoning, the AI in this case was able to identify the fact that the pressure of the vaporizer could be adjusted by operating the valve between the ethylene supply section and vaporizer.
Using reinforcement learning, the AI next derived proper operation of the valve. Simulations were used in which the reinforcement learning agents and ethylene pressures were changed in various ways. Since identification of the single valve that needed to be adjusted was done using logical reasoning, training was completed with fewer searches (number of simulations). In this case, the AI was able to learn the optimal operation using the PPO method in a few hours.
Upon evaluation, the optimal action (valve operation value) could be derived by giving the current sensor information to the reinforcement learning agent as an available state (Fig. 6).
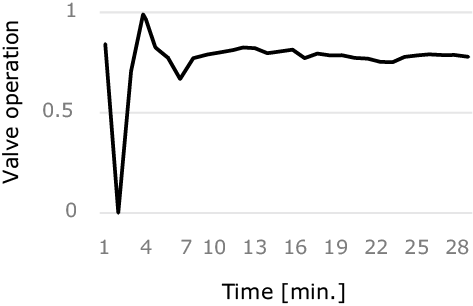
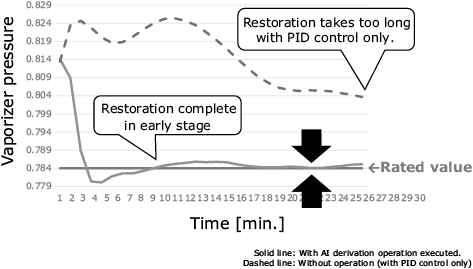
Fig. 7 shows the change in the vaporizer’s pressure when the derived operation was executed in the target plant. It is clear from this graph that the vaporizer’s pressure promptly returns to the rated value as soon as the countermeasure recommended by the logical thinking AI was executed. When letting the PID controller operate without human operation, the pressure changed as shown in the broken-line graph. Although the rated value is ultimately restored, it takes too long, leading to production loss during that time.
5. Conclusion
Combining logical reasoning with reinforcement learning, NEC’s leading-edge logical thinking AI has the potential to revolutionize industrial plant operation, providing expert-level decision-making capabilities to automated operation support. By applying logical reasoning to a given problem drawing on the plant’s operating manual and piping information stored in its knowledge base, the logical thinking AI can learn the optimal operation much faster than when reinforcement learning alone is used. Verification tests conducted using a chemical plant simulator have demonstrated the effectiveness of this technology and we are now planning to run validation tests in actual plants, while moving ahead with research and development aimed at facilitating practical deployment of this technology.
References
- 1)S. Kubosawa et al. : Synthesizing Chemical Plant Operation Procedures using Knowledge, Dynamic Simulation and Deep Reinforcement Learning, Proceedings of the SICE Annual Conference 2018
- 2)Y. Machida et al. : Vinyl Acetate Monomer (VAM) Plant Model: A New Benchmark Problem for Control and Operation Study, Dynamics and Control of Process Systems, including Biosystems (DYCOPS-CAB2016)
- 3)
- 4)J. Schulman et al. : Proximal Policy Optimization Algorithms, arXiv preprint arXiv:1707.06347 2017
 Omega Simulation Co., LTD.
Omega Simulation Co., LTD.Authors’ Profiles
ONISHI Takashi
Assistant Manager
Security Research Laboratories
Assistant Manager
Security Research Laboratories
KUBOSAWA Shumpei
Assistant Manager
Security Research Laboratories
Assistant Manager
Security Research Laboratories
SADAMASA Kunihiko
Principal Researcher
Security Research Laboratories
Principal Researcher
Security Research Laboratories
SOEJIMA Kenji
Senior Manager
Security Research Laboratories
Senior Manager
Security Research Laboratories