
Global Site
Breadcrumb navigation
Upcoming Features of NumPy-like library for SX-Aurora TSUBASA Vector Engine and Heterogeneous Systems
Technical ArticlesNov. 1, 2022
Shota KURIHARA (Numerical Library Engineer), Platform Service Division, NEC Solution Innovators, LTD.
Arihiro YOSHIDA (Numerical Library Manager) Platform Service Division, NEC Solution Innovators, LTD.
Ryusei OGATA (Numerical Library Manager) Advanced Platform Division, NEC Corporation
NumPy is a very important library in AI and scientific computing fields. To accelerate NumPy scripts with the Vector Engine (VE) of SX-Aurora TSUBASA, NEC provides a Python library named NLCPy that is based on the NumPy's API.
NEC also provides a Message Passing Interface (MPI) library for Python on SX-Aurora TSUBASA systems, which is named mpi4py-ve. mpi4py-ve supports MPI communications for Vector Host (VH) and VE. The available communication paths are VH-VH, VH-VE, and VE-VE. The available objects on VH side is the numpy.ndarray, and on VE side is the nlcpy.ndarray.
In addition, we provide a Python library for heterogeneous systems named OrchesPy, which makes it easy to port a NumPy script to different types of devices such as VE and GPGPU.
In this article, fist we describe the overview of NLCPy, mpi4py-ve, and OrchesPy, and then we introduce their upcoming features.
Introduction of NLCPy

In short words, NLCPy is a NumPy-like library accelerated with SX-Aurora TSUBASA. Python programmers can use NLCPy from an x86 server (VH) of SX-Aurora TSUBASA. NLCPy provides a subset of NumPy's API, therefore Python programmers can utilize VE computing power just by replacing module name "numpy" with "nlcpy". When using NLCPy, computation will be performed on VE, and data transfer between VH and VE will be done automatically.
Introduction of mpi4py-ve
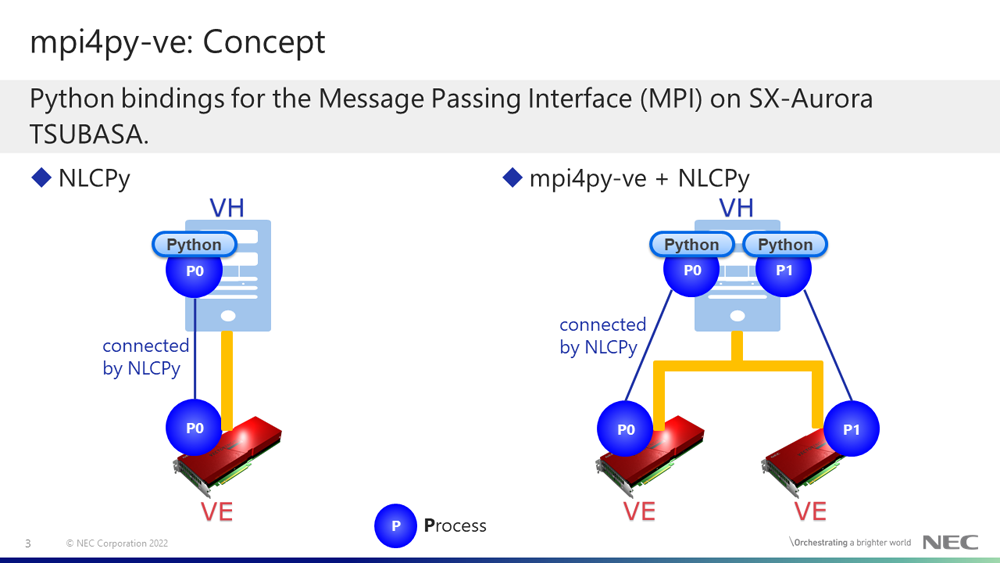
mpi4py-ve is an extension to mpi4py with SX-Aurora TSUBASA systems. mpi4py is a Python biding library of the Message Passing Interface (MPI) for CPU and is published as an OSS. The preview version (v0.1.0.b1) of mpi4py-ve has published since April 2022. The above figures show the execution image of NLCPy and mpi4py-ve. When using only NLCPy, a Python script runs on a single VH process and NLCPy on the VH process creates a VE process. The VH process and the VE process are connected by NLCPy, therefore the data transfer between VH and VE can be performed by NLCPy. When using NLCPy with mpi4py-ve, multiple processes are created on VH and NLCPy on each VH process creates VE processes on each VE. By using mpi4py-ve routines, data transfer between VH-VH, VH-VE, and VE-VE can be performed.
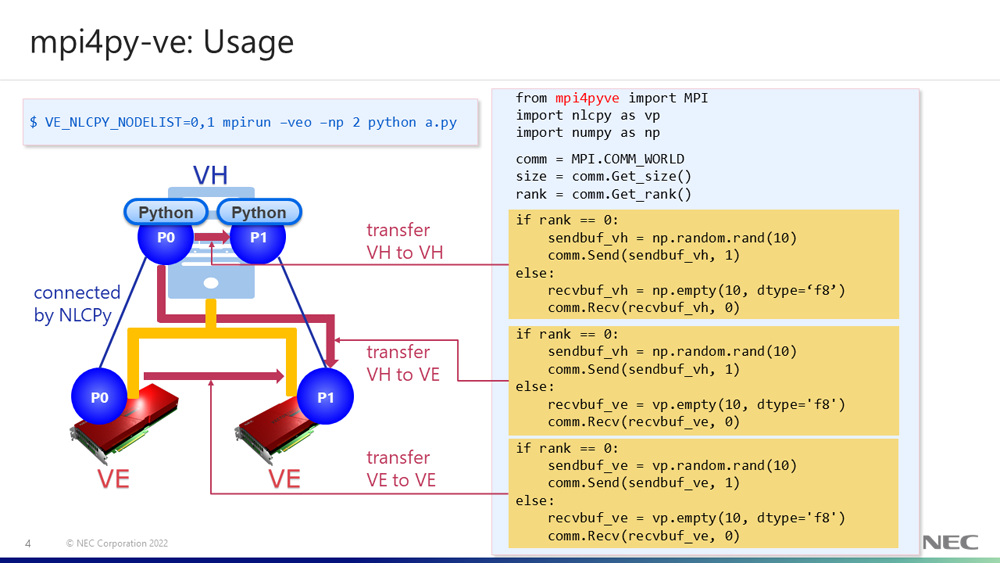
The slide shows the usage of mpi4py-ve. The first highlighted part of the right figure corresponds to the transferring from one VH process to another VH process. The second highlighted part corresponds to the transferring from a VH process to a VE process. The last highlighted part corresponds to the transferring from one VE process to another VE process. There is available for MPI communications by passing to mpi4py-ve routines with a numpy.ndarray object for the VH side buffer and an nlcpy.ndarray object for the VE side buffer. You can select the execution VE devices by specifying the IDs for an environment variable "VE_NLCPY_NODELIST".
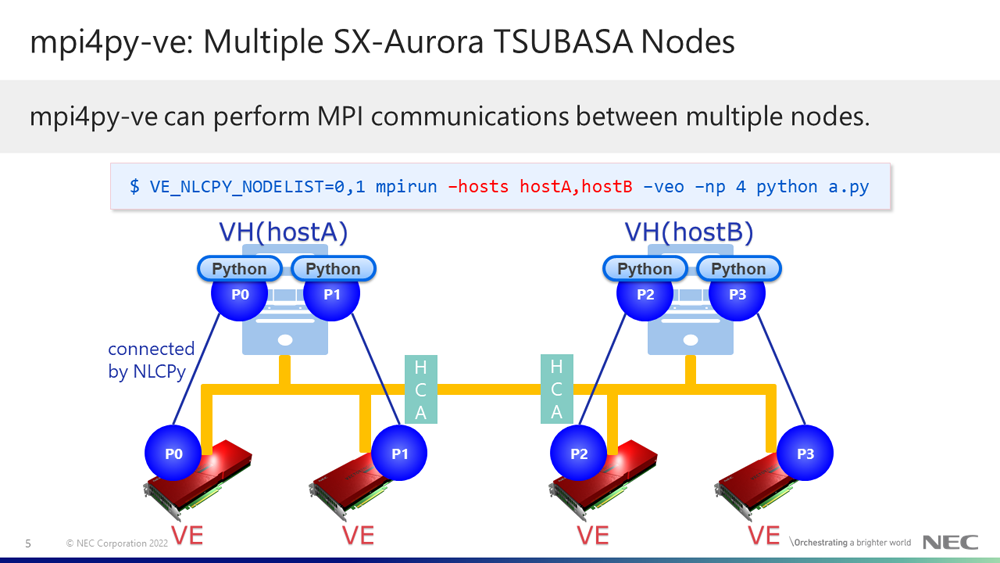
mpi4py-ve also supports MPI communications for the multiple SX-Aurora TSUBASA nodes to specify the "-hosts hostA,hostB,..." option with the "mpirun" command.
Introduction of OrchesPy
In this section, we introduce our activity for heterogeneous computing by CPU-VE-GPU collaboration.
Recently, accelerators have been widely used for achieving better performance. A host is usually a Linux server. The host controls execution of accelerators and performs I/O operations. Accelerator is various hardware for computing: for example, GPU, Vector Engine, and so on.
In Python, there are several NumPy compatible libraries for accelerators for ease of porting NumPy programs: for example, CuPy for NVIDIA CUDA GPU and NLCPy for SX-Aurora TSUBASA vector engine. However, for porting NumPy programs to heterogeneous systems, there is an issue with many code modifications to run a program on accelerators or to move part of program from an accelerator to another.
To solve the issue, NEC proposes a new Python library OrchesPy.
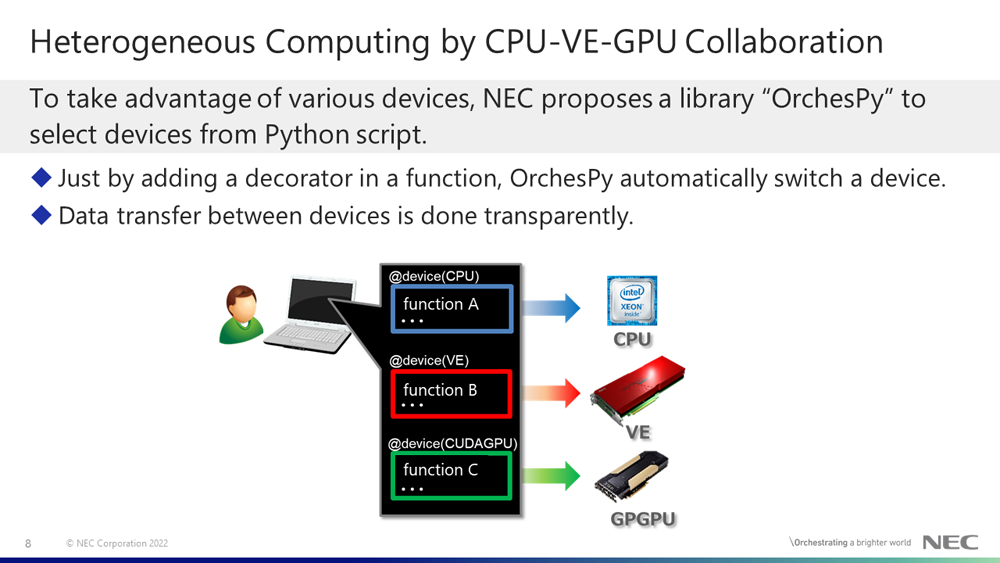
The name "OrchesPy" comes from Orchestrate and Python. This means the library to orchestrate NumPy-like libraries for various devices. OrchesPy has published preview version (v0.1.0b1) since April 2022. When using OrchesPy, just by adding a directive-like decorator at the head of a function, the function is run on the specified device. To move part to another device, you need to change only the argument of the decorator. Transferring data between devices is done transparently.
Next section, we introduce our upcoming features.
Upcoming features of mpi4py-ve

mpi4py-ve will support Direct Memory Access (DMA) in November 2022. In the preview version (v0.1.0b1), mpi4py-ve cannot transfer data directly between VEs. In other words, the data transfer between VEs has to go through VH. To overcome this weakness, mpi4py-ve will support DMA. It enables data to be transferred directly between VEs. The above figure shows the ping-pong (VE-VE) performance comparison with a preview version (v0.1.0b1) and the upcoming version (v1.0.0). The ping-pong is a well-known benchmark that measures bandwidth for data transfers between 2 MPI processes. The performance of the preview version is almost 2 GB/s, and the performance of the upcoming version is almost 12 GB/s, therefore the upcoming version achieves almost 6 times faster performance than the preview version.
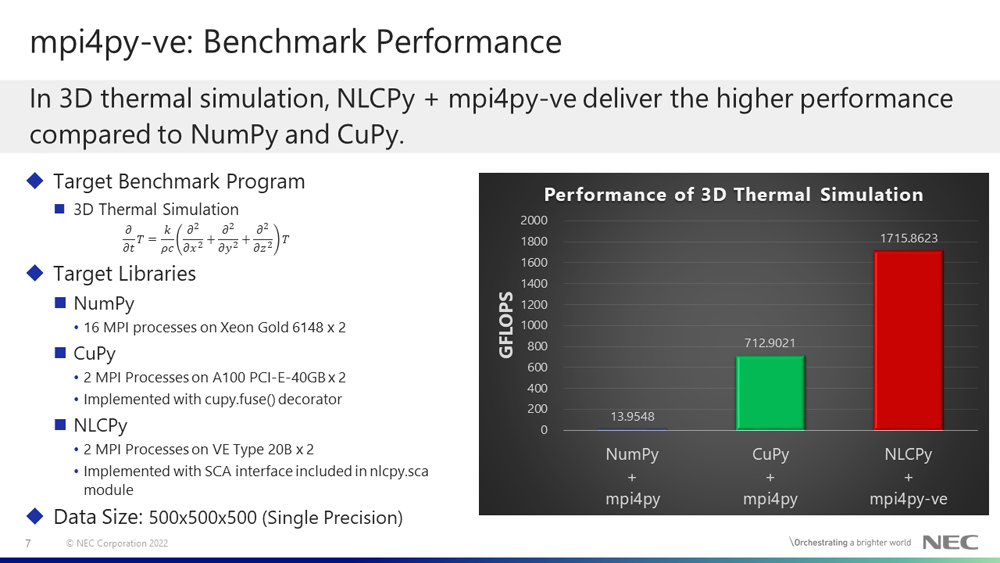
We measured a performance for the 3D thermal simulation with MPI communication. The above chart shows performance comparison of three libraries: NumPy, CuPy, and NLCPy. The left bar in the chart is the performance of NumPy + mpi4py when running 16 MPI processes on 2 nodes (Intel Xeon Gold 6148). The middle bar in the chart is the performance of CuPy + mpi4py when running 2 MPI processes on 2 GPU cards (A100 PCI-E-40GB). The right bar in the chart is the performance of NLCPy + mpi4py-ve when running 2 MPI processes on 2 VE cards (Type 20B). Our benchmark program for NLCPy used mpi4py-ve (upcoming version) to communicate between MPI processes, while that for NumPy and CuPy used mpi4py.The data size in benchmarking is 500x500x500 and the data type is single precision. As shown the above figure, NLCPy + mpi4py-ve show the highest performance.
Upcoming features of OrchesPy and NLCPy
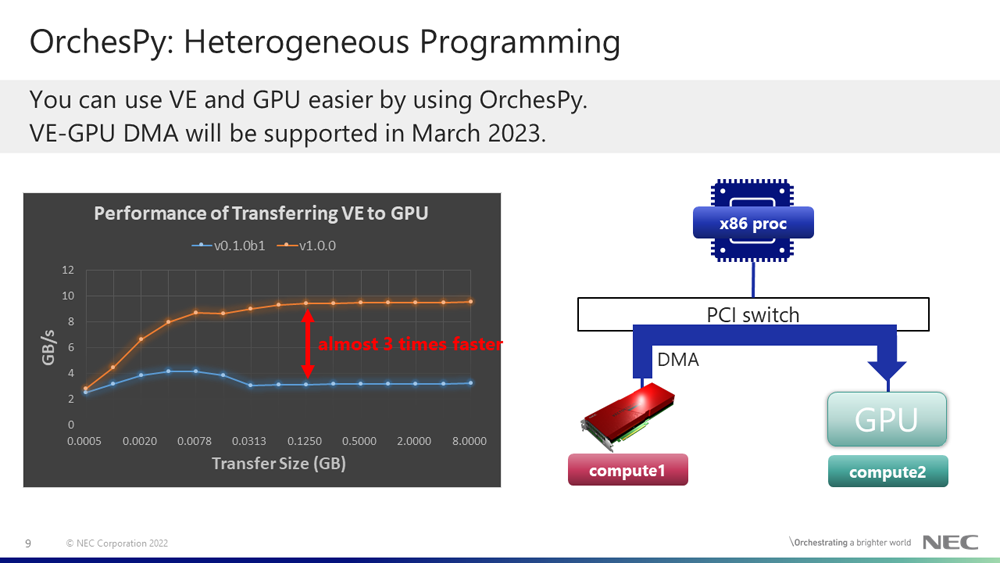
OrchesPy will support VE-GPU DMA in March 2023. The left figure shows the performance of transferring data from VE to GPU, which compared with the preview version (v0.1.0b1) and the upcoming version (v1.0.0). The performance of the preview version is almost 3 GB/s, and the performance of the upcoming version is almost 10 GB/s, therefore the upcoming version achieves almost 3 times faster performance than the preview version.

In addition, OrchesPy will support a device selection feature for VE and GPU. By specifying a device ID in the argument of the decorator, you can select the execution VE device or GPU device. If the routines or operations included in the decorated functions run asynchronously, you can utilize multiple device computing power.
Related to this feature, NLCPy will also support the VE device selection feature in November 2022. You can select the execution VE device by using Python "with" context manager.
Production Roadmap
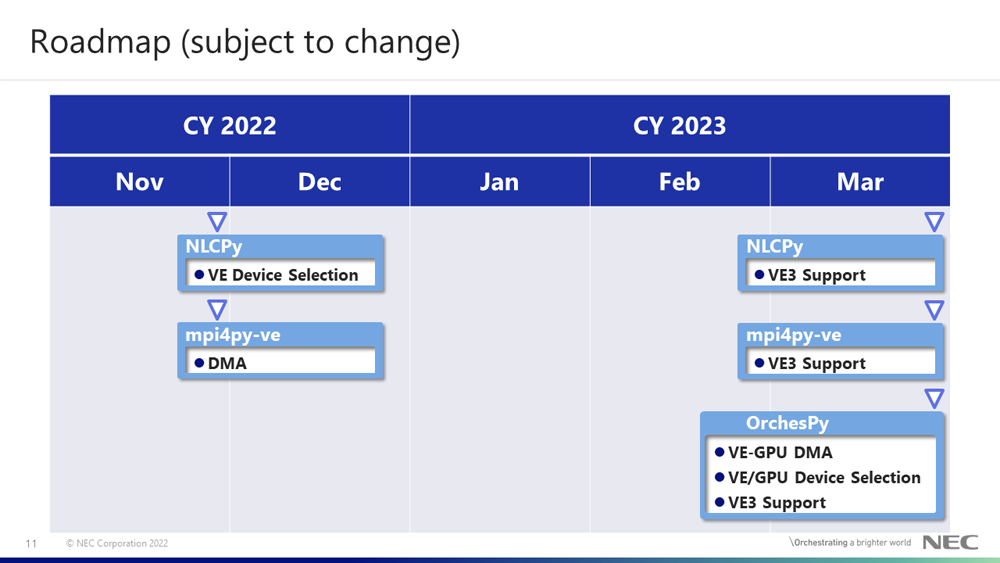
We summarize the production roadmap. In November 2022, NLCPy will support the VE device selection feature, and mpi4py-ve will support the DMA. In March 2023, OrchesPy will support VE-GPU DMA and VE/GPU device selection feature. In addition, we plan to support VE3 architecture for NLCPy, mpi4py-ve, and OrchesPy in March 2023. Note that this schedule is subject to change without notice.
Conlusions
We introduced Python libraries NLCPy, mpi4py-ve, and OrchesPy, which provided by NEC.
- NLCPy: NumPy-like library accelerated with SX-Aurora TSUBASA.
- mpi4py-ve: MPI library for Python on SX-Aurora TSUBASA systems.
- OrchesPy: Python library for heterogeneous systems, which makes it easy to port a NumPy script to different types of devices such as VE and GPGPU.
We also introduced upcoming features of them.
- NLCPy will support VE device selection feature in November 2022.
-
mpi4py-ve will support DMA in November 2022.
- The upcoming version of mpi4py-ve will deliver almost 6 times faster performance for transferring data between VE and VE than the preview version of it.
-
OrchesPy will support VE-GPU DMA and VE/GPU device selection feature in March 2023.
- VE-GPU DMA achieves almost 3 times faster performance than the preview version of OrchesPy.
The online manuals of NLCPy, mpi4py-ve, and OrchesPy are available at the following URLs:
 https://sxauroratsubasa.sakura.ne.jp/documents/nlcpy/en/index.html
https://sxauroratsubasa.sakura.ne.jp/documents/nlcpy/en/index.html