
Global Site
Breadcrumb navigation
Summarizing long videos into shorter videos with text according to user instructions:
Video recognition AI × LLM
Featured Technologies December 14, 2023

A constellation of videos are taken in various settings in modern society, but not all of them are effectively used. While AIs are more commonly used for video analysis, most of them still remain at visualization based on single functions such as object identification and human detection―there is no commonplace technology that analyzes the comprehensive meaning and suggests possible values.
This video recognition AI × LLM technology that NEC recently developed (we call this technology the “Video Recognition AI x LLM technology”) is effective for bringing out any and all values that may potentially be found in long videos. We spoke with the researchers about the details of this technology and use cases.
Aiming for a video version of ChatGPT

Senior Principal Researcher & Director (Head of Research Group)
Jianquan Liu
― What kind of technology is the descriptive video summarization technology?
Liu: This technology extracts from a long video only the scenes that meet the criteria specified by the user and then automatically generates a summary that explains those scenes. Originally, the R&D started with the concept of producing a “video summary based on the user's point of view.” This technology enables users to efficiently get information they want in short time, without having to watch the whole long video. The research paper explaining this concept won the Best BNI Paper Award at the ACM Multimedia 2022, the worldwide premier conference, held in October last year.*1
Why the “user’s point of view” is necessary is because which scenes in a video are meaningful differs for each user. Think about a video from a wedding for example. From the bride and groom’s perspective, they would want a digest video that is centered around their happy moments together while also including a well-balanced compilation of scenes with their friends and relatives. On the other hand, the bride’s parents may want more from the parts with the bride’s relatives, centering on the bride’s scenes. What meaning does the user see in the video, and what value does the user want to draw out of it... The deeper you get in video analysis, the more likely you are to hit a limit in uniform analysis. That is why we must have the user’s point of view.
The generation of a summary is added to perform up to the analysis of the video. While many cognitive and recognition engines are used in present-day video analysis technology, most of them remain only able to visualize the detection target by putting frames in the video images, and no specific analysis was performed. Having said that, for the new technology, we aimed to generate a summary text in the form of storytelling to show in an easy-to-understand manner what is happening in the images.
We hammered out this concept in October last year, and development rapidly progressed with the emergence of a large language model (LLM) called ChatGPT, which was released soon after. ChatGPT was “user-centric” and “narrative,” both of which were exactly the elements that we were aiming for in our concept. The new technology makes the action according to the user’s instruction and returns a user-friendly output in natural language. You can say that the technology we aimed for is like a video version of ChatGPT. We worked on R&D by exploring how we could develop a technology by using an LLM that contains this ChatGPT.
- *1 ACM Multimedia 2022 was held in Lisbon, Portugal from October 10 through 14. BNI is an abbreviation for Brave New Ideas. Award-winning research paper: Compute to Tell the Tale: Goal-Driven Narrative Generation,
 https://doi.org/10.1145/3503161.3549202
https://doi.org/10.1145/3503161.3549202
Developing the technology based on LLM and NEC’s proprietary technology platform

Satoshi Yamazaki
― What breakthrough made this technology possible?
Yamazaki: There were broadly three challenges to achieve this concept. The first challenge was to interpret the user’s intention. The second challenge was to extensively know what is happening in the video. The third challenge was to combine the two elements mentioned earlier and select only the parts that match the user’s intention. Overcoming these challenges became much simpler with the emergence of LLMs. In particular, LLMs contributed greatly to the first and third challenges. We were able to effectively use advanced natural language processing.
Nevertheless, you can’t just use LLMs as they are. There are some hacks to effectively and efficiently handling them. The skills to successfully handle generative AI are in the area of prompt engineering, which is currently attracting attention and requires specialized and advanced know-how close to programming. So we had Mr. Chen join our team as prompt engineer, which contributed to smooth development.
Chen: Yes. Prompt engineering may not be commonly known. For example, LLMs tend to give precision outputs when split text is input rather than a long sentence. Using that characteristic, I made adjustments so that more accurate summary text can be produced.
Yamazaki: And you did it pretty quickly. We accomplished speedy completion thanks to your agile performance.

Yen-Ping Chen
Chen: Yes. I built a prototype little by little starting from the creation of a demo of the concept. I repeated updates every two months or so. It was around March that we decided on the general framework of using an LLM, so we were able to release it in about half a year.
Yamazaki: Yes, that’s right. It was so helpful.
Now, the remaining second challenge is actually an area that NEC has been good at. NEC has a range of engines that perform video recognition and video analysis. Since several years ago, we have been working on building a platform that allows for an integrated handling of all these individual engines. That is because video analysis on the site needs to support various approaches, including object identification and person tracking, for different scenes. We believed that it is necessary to establish a platform that enables comprehensive access to these functions to use them in combination as needed. This preparation also contributed to get the development of this technology smoothly on track.
Liu: As Mr. Yamazaki just mentioned, NEC has a platform that can combine more than 100 recognition engines, including open source software (OSS), for use in analysis. The ability to fully make use of diverse video analysis methods is one of our strengths.
NEC also has an original technology that extracts meta data from videos using these engines and represents this data in a compact, graph structure. Since we have our own multimedia database that can efficiently process this graphic structure, we can quickly perform searches and analyses.
We also use a technology that documents what is shown in images on a fact basis. It is the foundation model developed by NEC Laboratories America. The key is that it is based on facts―for there is a problem that most generative AIs are “liars.” Technically, this is called “hallucination.”* Since our new technology generates text based on facts, it is structurally less prone to generating lies by design.
Applicable to a wide range of purposes, centering on improving efficiency in video checks

― Please tell us about some specific use cases.
Liu: First of all, our first target is use in insurance investigations. This technology can be applied to drive recorder videos, where the investigator instructs the system to extract only the scenes from the accident and gets the relevant images and the explanations thereof. We are expecting use in creating accident investigation reports.
Yamazaki: Because the system automatically organizes the relevant scenes and summaries and creates a draft out of them, the investigator only needs to do simple, minor corrections to complete the report. The demo system is already created, and we are currently running simulations by which we are expecting to prove that time spent on report documentation can be reduced by half. We plan to conduct further demonstrations for more specific verifications.

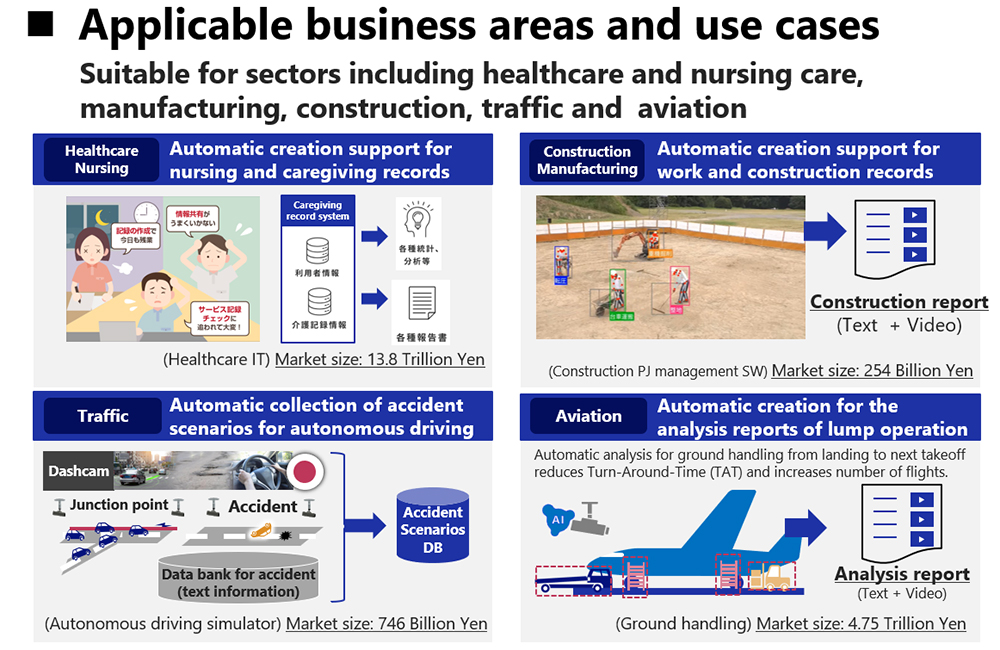
Liu: I think that it can be applied to other different scenes as well. For example, by applying this technology to camera images of a factory’s production line, you can streamline work checks at key points such as finished product inspections. You will no longer need to check the 24 hours worth of video images for the day, but merely need to read through the report generated by this technology. Other possible applications include journaling by nurses and caregivers, shift check at shops, and aircraft ground handling* at airports. This technology can be widely applied to improve the efficiency of video checking. It can also be applied to the B2C area. An example would be efficiently creating a digest video that follows a specific player in a sport game video.
Yamazaki: Another point worth mentioning is that such reports and digests can be created by chatting with the AI. With no special program knowledge required, users can give instructions using plain language. Since an LLM developed by NEC is used, fine tuning can be easily achieved according to industry or scene. Secure, on-premise operations are also possible. Our video search technology that we have long studied is now made into a technology that is closer and more familiar to the users. Please look forward to this technology.
- *Aircraft ground handling: defines the servicing of an aircraft while it is on the ground, specifically from its arrival at the airport to its departure from the airport, usually involving operations such as cargo loading and passenger guiding.


Video Recognition AI x LLM technology extracts scenes that match the user’s specifications from a lengthy video and outputs the relevant scenes along with the explanation. Since it operates based on instructions entered by users in natural language, it works like a video version of ChatGPT. This proprietary technology runs on a platform that analyzes videos by combining the various video recognition engines developed to date by NEC, extracting meta data from videos using these engines and representing this data in a compact, graphic structure. In addition, another technology that prevents hallucinations by documenting what is shown in images on a fact basis coordinates with the LLM to deliver this new technology.
- ※The information posted on this page is the information at the time of publication.