
Global Site
Breadcrumb navigation
Increasing the Processing Speed of Edge AI by up to Eight Times
Gradual Deep Learning-Based Object Detection Technology
Featured Technologies November 16, 2021

In an era when many devices are connected to the Internet due to the progress of IoT, computing must now be processed on edge terminals installed in the field.
The "gradual deep learning-based object detection technology" announced by NEC is a technology which improves the processing speed of edge terminals equipped with AI chips in an innovative manner. We spoke with two researchers about how this technology works and its advantages.
A technology that draws out the latent performance of edge AI chips

Senior Principal Researcher
Takashi Takenaka
― What kind of technology is "gradual deep learning-based object detection technology?"
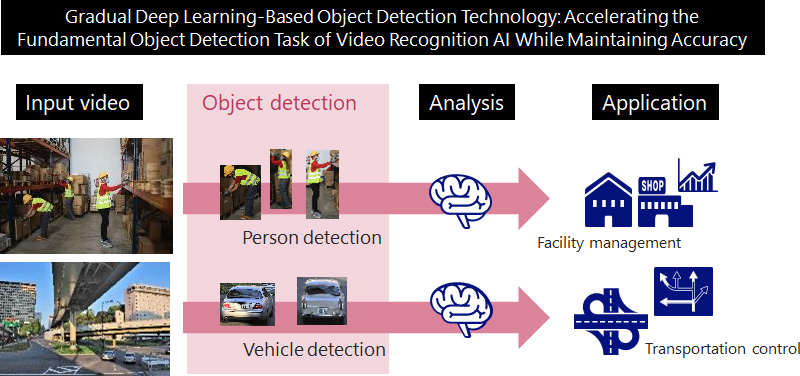
Takenaka: It is a technology that can rapidly run object detection, which is a basic processing task in various types of image recognition AI, while maintaining recognition accuracy even in an edge environment with restrictions on processing capacity.
Edge terminals equipped with AI chips are extremely important devices that are expected to be introduced in a wide range of scenarios around the world in the future. In particular, it is likely to become an essential technology on the front lines of DX which applies video recognition such as transportation control in smart cities and cargo management in logistics.
Edge terminals that can reduce communication costs and process information in real time in the field are computers which will form the basis of the efficient and safe application of sensed data. We expect that 2.9 billion edge terminals equipped with AI chips will be deployed around the world by 2025.
However, the processing capacity of edge terminals is necessarily restricted due to the fact that edge terminals are miniature terminals installed close to cameras or around outdoor and other sensors. For example, since edge terminals must be sealed airtight due to exposure to wind and rain outdoors, it is not possible for them to be equipped with a fan to promote exhaust heat, and they are unable to use sufficient power.
Even indoor terminals are unable to sufficiently release heat or cool down due to restrictions on durability and the installation location area. Typically, when using a server GPU to run recognition AI, you would apply roughly 300W of power for processing. However, with edge terminals you are limited to 10 to 20W at the most particularly with fanless models for outdoor use.
So the question of how to maintain recognition accuracy and accelerate the processing under such restrictions has been an issue.
Gradual deep learning-based object detection technology is a technology that demonstrates one way to solve this problem. It was developed as a technology that draws out the latent performance of edge AI chips as much as possible.
Achieves a maximum acceleration of up to eight times while preserving recognition accuracy

Assistant Manager
Yoshikazu Watanabe
― What sort of mechanism did you use to solve this problem of maintaining recognition accuracy and accelerating the processing under restrictions on power consumption?
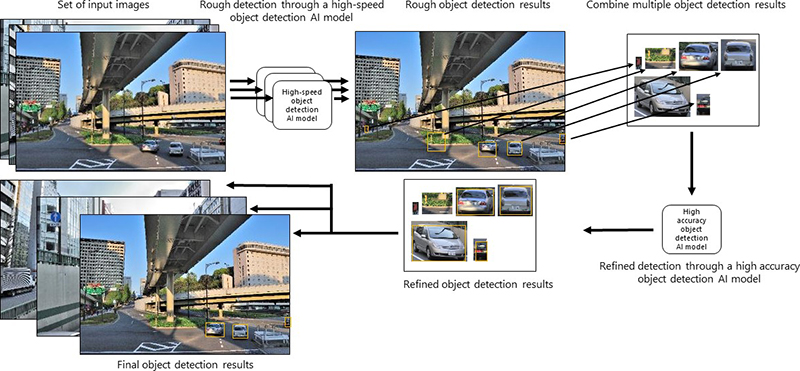
Watanabe: We used multiple object detection AI models to design a framework in which the accuracy gradually increases over time.
In this case, we used a high-speed object detection AI model and a high accuracy object detection AI model to successfully validate the technology. The high-speed model roughly narrows down the areas with objects in a video image and then the high accuracy model correctly detects the objects.
This type of two-stage processing did exist previously. However, an important point is that we created a unique mechanism which aggregates the images in between the first- and second-stage processing.
AI chips have many computation resources, and they are proficient at parallel processing. Therefore, instead of processing a few small images during one execution, they are able to process many large images efficiently and at high-speed.
In previous forms of two-stage processing, the object candidates discovered during the first-stage processing were directly sent to the second-stage processing, so only a fraction of the operation resources on the chip were able to be used. Therefore, the processing was slow.
In our technology, we built a mechanism which creates a large image that aggregates the processing results from the first stage and then passes it all at once to the second-stage processing. This makes it possible to effectively utilize the computation resources of the AI chip.
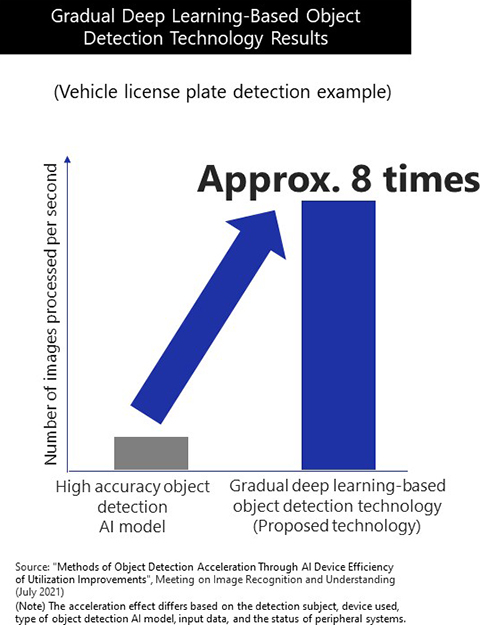
In a test designed to detect vehicle license plates from video, we were able to confirm that this new technology accelerates the processing speed by a maximum of eight times compared to using a high accuracy model alone while still preserving a high level of accuracy. As a result, we successfully lowered the power consumption per throughput.
Takenaka: Because there is a trade off relationship between recognition accuracy and speed, when one of those aspects is prioritized in conventional methods, the other is sacrificed. The method that we developed is able to reconcile recognition accuracy and speed by utilizing two or more models.
Watanabe: Moreover, the models can also be replaced. If higher accuracy or faster models are created, we can change to those models and update the technology.
Depending on the situation, it might be better to use three models or even switch the second-stage processing (model used, etc.) based on the processing results of the first stage. The key point of this technology is that we were able to build an edge AI acceleration system from a higher perspective by creating a new framework that aggregates the result images of the first processing and then performs the final processing.

Support for various detection objects
― In what ways can this new technology be useful to society?
Takenaka: First, we believe that achieving an acceleration of edge AI will enable us to expedite various solutions which utilize edge terminals. In addition, achieving such an acceleration technology will enable one edge terminal to connect to many cameras and sensors as a result.
We believe that this will help spur the adoption of DX which utilizes edge AI. In terms of a specific solution, we could apply it to assessing the volume of traffic and transportation control in a smart city based on detecting vehicles and license plates, for example.
Another area that we think has significant potential is in the facility management of warehouses and buildings. This system can support multiple object detection AI models, so it can adapt to various detection objects.
For example, if we utilize an AI model that detects human posture, then it would become able to detect a person that has fallen. We believe that we can effectively utilize the advantages of edge computing which finds problems from camera images in real time. In addition, we should be able to propose various solutions in accordance with our technology and the implementation needs of customers.
Watanabe: We believe that we should be able to create a way to automatically adjust the parameters according to the needs of customers. It is a system that automatically runs recognition AIs at high-speed when you input the data. We are now simultaneously considering ways to deploy this technology that avoid placing a burden on our users as much as possible.
Takenaka: In terms of our immediate milestones, we are aiming to embed and sell this technology in NEC's core products for edge AI during the next fiscal year. With the goal of satisfying our users, we will continue to diligently develop this technology going forward.

- ※The information posted on this page is the information at the time of publication.